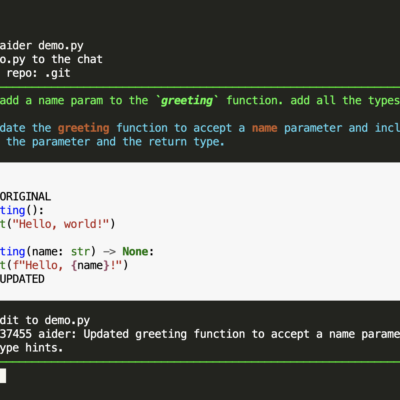
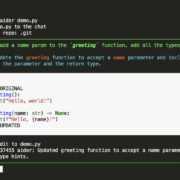
Tóm tắt nhanh
- VoxCPM2 là phiên bản mới nhất của hệ thống text-to-speech mã nguồn mở do OpenBMB phát hành (tháng 4/2026) – mô hình 2B tham số, train trên hơn 2 triệu giờ dữ liệu speech đa ngôn ngữ.
- Hỗ trợ 30 ngôn ngữ bao gồm tiếng Việt, Trung, Anh, Nhật, Hàn, Pháp, Đức, Tây Ban Nha, Ả Rập, Hindi, Indonesia, Thái, Khmer, Lào, Miến Điện…
- Tokenizer-free với kiến trúc diffusion autoregressive end-to-end – không dùng discrete tokenization, output speech tự nhiên và biểu cảm hơn.
- 3 chế độ voice generation: Voice Design (tạo voice mới từ mô tả văn bản), Controllable Cloning (clone voice từ audio reference), Ultimate Cloning (clone tuyệt đối với reference audio + transcript).
- Output 48kHz studio-quality với AudioVAE V2 – chấp nhận reference 16kHz, output 48kHz, built-in super-resolution không cần upsampler ngoài.
- Real-time streaming: RTF ~0.3 trên RTX 4090; xuống còn ~0.13 với Nano-vLLM hoặc vLLM-Omni (API OpenAI-compatible).
- License Apache-2.0 – free for commercial use. VRAM cần khoảng 8GB.
TTS mã nguồn mở đã đuổi kịp ElevenLabs
Trong vài năm qua, ElevenLabs gần như độc tôn ở thị trường text-to-speech chất lượng cao với voice cloning. Nhưng họ closed-source, trả tiền theo character, và data của bạn nằm trên server của họ. Các alternative open-source trước đây (Tortoise TTS, XTTS-v2, OpenVoice) thường có một trong các vấn đề: chất lượng kém hơn ElevenLabs đáng kể, không hỗ trợ voice cloning xịn, hoặc không cho thương mại.
VoxCPM2 ra mắt tháng 4/2026 đã thay đổi cuộc chơi. Đây là phiên bản thứ ba trong dòng VoxCPM của OpenBMB (sau VoxCPM-0.5B từng top #1 HuggingFace Trending tháng 9/2025 và VoxCPM1.5 top #1 GitHub Trending tháng 12/2025). Với 2B tham số, train trên 2M+ giờ speech, hỗ trợ 30 ngôn ngữ, output 48kHz, license Apache-2.0 – đây là một trong những TTS mã nguồn mở mạnh nhất hiện nay, và quan trọng nhất: free cho cả mục đích thương mại.
Mô hình built trên backbone MiniCPM-4 (cũng của OpenBMB), thừa hưởng triết lý “small but mighty” – chạy được trên một GPU consumer-grade tầm RTX 4090.
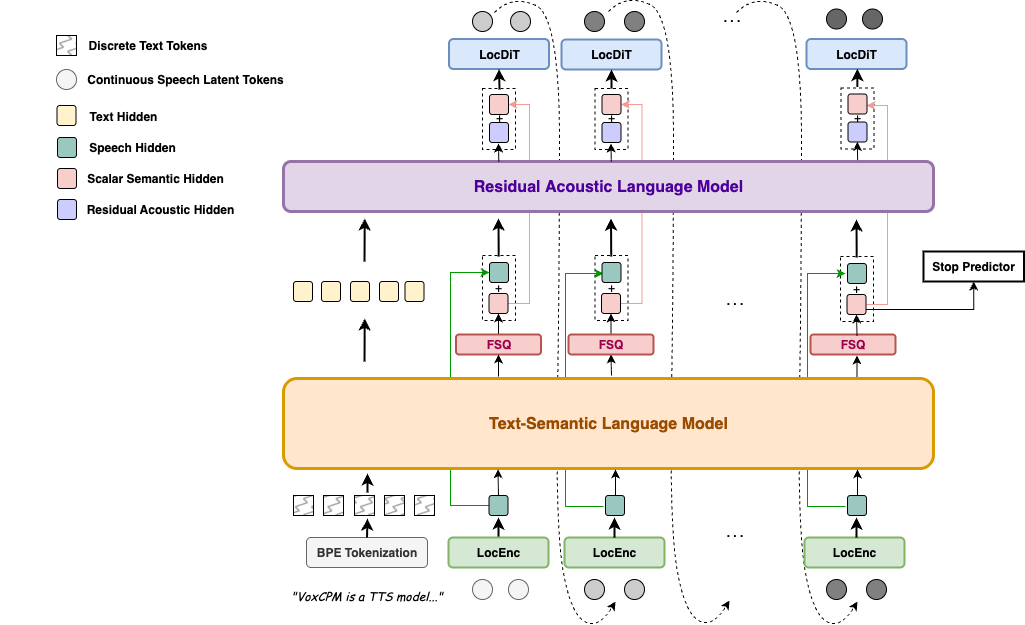
Các tính năng nổi bật của VoxCPM2
30 ngôn ngữ multilingual native
Đây là khác biệt lớn nhất so với các phiên bản trước (vốn chỉ có Trung + Anh). VoxCPM2 hỗ trợ: Arabic, Burmese, Chinese, Danish, Dutch, English, Finnish, French, German, Greek, Hebrew, Hindi, Indonesian, Italian, Japanese, Khmer, Korean, Lao, Malay, Norwegian, Polish, Portuguese, Russian, Spanish, Swahili, Swedish, Tagalog, Thai, Turkish, Vietnamese.
Đặc biệt, không cần language tag – bạn nhập text bằng ngôn ngữ nào, model tự nhận biết và synthesize. Có thể mix nhiều ngôn ngữ trong cùng một đoạn (ví dụ tiếng Việt xen tiếng Anh) mà vẫn flow tự nhiên.
Ngoài ra còn hỗ trợ một số phương ngữ Trung Quốc: Quảng Đông, Thượng Hải, Tứ Xuyên, Hokkien…
Voice Design: Tạo voice mới từ mô tả văn bản
Đây là feature thực sự đột phá. Không cần bất kỳ reference audio nào – bạn chỉ cần mô tả voice bằng natural language: gender, tuổi, tone, emotion, pace. Format: đặt mô tả trong dấu ngoặc đơn ở đầu text.
Ví dụ: "(A young woman, gentle and sweet voice)Xin chào, chào mừng đến với VoxCPM2!" – model tự tạo voice nữ trẻ, giọng ấm áp, không cần record giọng mẫu nào.
Cực kỳ hữu ích cho audiobook, podcast, game character – bạn dễ dàng tạo hàng chục nhân vật với giọng riêng biệt mà không cần thuê voice actor.
Controllable Voice Cloning
Upload một reference clip ngắn (vài giây), model clone timbre. Vẫn dùng được control instruction để điều chỉnh tốc độ, emotion, style. Ví dụ thêm "(slightly faster, cheerful tone)" để tăng tốc độ và làm giọng vui vẻ hơn, trong khi vẫn giữ nguyên timbre gốc.
Ultimate Cloning: tái tạo từng nuance giọng nói
Cho voice cloning chất lượng tối đa, cung cấp cả reference audio và transcript chính xác. Model dùng audio-continuation approach để tái tạo từng vocal nuance: timbre, rhythm, emotion, style. Đây là mode same với VoxCPM1.5 và phù hợp khi bạn cần clone voice giống thật nhất có thể.
48kHz studio-quality output
AudioVAE V2 dùng asymmetric encode/decode design: chấp nhận reference 16kHz nhưng output trực tiếp 48kHz. Built-in super-resolution nghĩa là không cần upsampler ngoài như AudioSR. Kết quả audio rich, full-frequency – phù hợp ngay cho production.
Context-aware synthesis
Model tự suy luận prosody và biểu cảm phù hợp từ nội dung text. Một câu hỏi tự động lên tone ở cuối, một câu cảm thán tự nhiên có emphasis. Không cần markup SSML phức tạp.
Real-time streaming và production deployment
RTF (real-time factor) ~0.3 trên RTX 4090 với PyTorch chuẩn. Tích hợp với Nano-vLLM-VoxCPM hoặc vLLM-Omni chính thức xuống còn ~0.13 – thực sự real-time với độ trễ cực thấp. vLLM-Omni expose endpoint OpenAI-compatible /v1/audio/speech – drop-in replacement cho OpenAI TTS API.
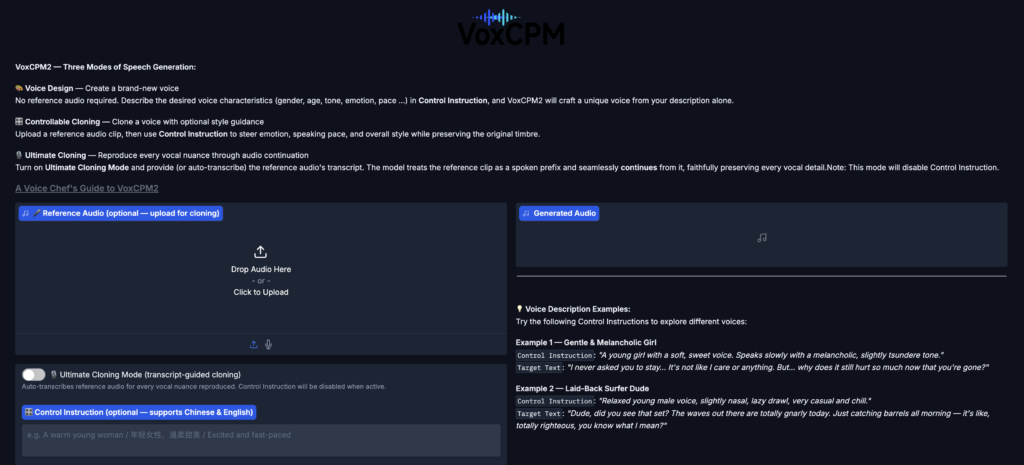
Hướng dẫn cài đặt VoxCPM2
Yêu cầu
- Python 3.10 ≤ version < 3.13
- PyTorch 2.5.0
- CUDA 12.0
- GPU NVIDIA với ~8GB VRAM (RTX 3070/4070 trở lên là đủ)
CPU và Apple Silicon (MPS) cũng chạy được nhưng chậm hơn nhiều.
Cài đặt qua pip
pip install voxcpmCài xong là sẵn sàng dùng. Weight model sẽ tự download từ HuggingFace lần đầu chạy.
Cài qua ModelScope (cho user Trung Quốc, tốc độ download nhanh hơn)
pip install modelscopeTrong code Python:
from modelscope import snapshot_download
snapshot_download("OpenBMB/VoxCPM2", local_dir='./pretrained_models/VoxCPM2')Sử dụng VoxCPM2: Workflow điển hình
Bước 1: Text-to-Speech cơ bản
from voxcpm import VoxCPM
import soundfile as sf
model = VoxCPM.from_pretrained(
"openbmb/VoxCPM2",
load_denoiser=False,
)
wav = model.generate(
text="VoxCPM2 là mô hình text-to-speech mã nguồn mở chất lượng cao.",
cfg_value=2.0,
inference_timesteps=10,
)
sf.write("demo.wav", wav, model.tts_model.sample_rate)Tham số cfg_value điều khiển expressiveness (giá trị cao hơn = biểu cảm mạnh hơn). inference_timesteps cân bằng giữa chất lượng và tốc độ – 10 là sweet spot.
Bước 2: Voice Design – tạo voice mới từ mô tả
wav = model.generate(
text="(A young woman, gentle and sweet voice)Xin chào, đây là một giọng mới được tạo từ mô tả văn bản.",
cfg_value=2.0,
inference_timesteps=10,
)
sf.write("voice_design.wav", wav, model.tts_model.sample_rate)Thử các mô tả khác: "(Middle-aged man, deep authoritative voice)", "(Elderly woman, soft warm tone)", "(Young energetic male, fast-paced)".
Bước 3: Voice cloning từ audio reference
Chuẩn bị file reference của bạn (đặt tên ví dụ my_voice.wav):
wav = model.generate(
text="Đây là giọng clone từ audio reference của tôi.",
reference_wav_path="my_voice.wav",
)
sf.write("clone_output.wav", wav, model.tts_model.sample_rate)Thêm control instruction để điều chỉnh style:
wav = model.generate(
text="(slightly faster, cheerful tone)Giọng cloned với style được điều chỉnh.",
reference_wav_path="my_voice.wav",
cfg_value=2.0,
inference_timesteps=10,
)Bước 4: Ultimate cloning cho chất lượng cao nhất
Khi cần clone voice ở mức tối đa, cung cấp cả audio reference và transcript chính xác:
wav = model.generate(
text="Đây là demo ultimate cloning với VoxCPM2.",
prompt_wav_path="my_voice.wav",
prompt_text="Transcript chính xác của audio reference.",
reference_wav_path="my_voice.wav",
)
sf.write("ultimate_clone.wav", wav, model.tts_model.sample_rate)Bước 5: Streaming API
Cho ứng dụng cần real-time (voice assistant, live narration):
import numpy as np
chunks = []
for chunk in model.generate_streaming(
text="Streaming text-to-speech với VoxCPM rất đơn giản!",
):
chunks.append(chunk)
wav = np.concatenate(chunks)
sf.write("streaming.wav", wav, model.tts_model.sample_rate)Bước 6: CLI cho batch và quick test
# Voice design
voxcpm design \
--text "VoxCPM2 mang lại chất lượng studio đa ngôn ngữ." \
--output result.wav
# Voice cloning
voxcpm clone \
--text "Demo voice cloning." \
--reference-audio my_voice.wav \
--output cloned.wav
# Batch processing nhiều câu
voxcpm batch --input texts.txt --output-dir outputs/Bước 7: Web demo
python app.py --port 8808Mở http://localhost:8808 để dùng giao diện web – phù hợp khi share cho team không muốn dùng code.
Production deployment với vLLM-Omni
Đối với multi-tenant serving production, dùng vLLM-Omni – extension chính thức của vLLM hỗ trợ native VoxCPM2:
uv pip install vllm==0.19.0 --torch-backend=auto
git clone https://github.com/vllm-project/vllm-omni.git
cd vllm-omni
uv pip install -e .
vllm serve openbmb/VoxCPM2 --omni --port 8000Server expose endpoint OpenAI-compatible:
curl http://localhost:8000/v1/audio/speech \
-H "Content-Type: application/json" \
-d '{"model":"openbmb/VoxCPM2","input":"Hello from VoxCPM2!","voice":"default"}' \
--output result.wavBạn có thể swap thẳng client OpenAI hiện tại sang endpoint này – không phải sửa code.
Một số mẹo và lưu ý
Đối với tiếng Việt, voice design hoạt động tốt nhất khi mô tả bằng tiếng Anh nhưng nội dung text bằng tiếng Việt – model train chủ yếu trên metadata mô tả tiếng Anh. Thử nghiệm với các mô tả khác nhau để tìm voice ưng ý.
Khi clone voice, chất lượng reference clip quyết định 80% chất lượng output. Reference nên: dài 5-30 giây, không nhiễu nền, không nhạc, giọng đều, không quá nhiều emotion biến thiên. Định dạng WAV 16kHz là đủ.
Tham số cfg_value (classifier-free guidance) là núm vặn quan trọng nhất: 1.5-2.0 cho voice tự nhiên, 2.5-3.0 cho expressive mạnh, >3.0 có thể artifact. Bắt đầu với 2.0 và adjust.
License Apache-2.0 cho phép thương mại không giới hạn – bạn có thể tích hợp VoxCPM2 vào product trả phí, ship trong app mobile, dùng cho audiobook commercial – tất cả đều OK.
VoxCPM2 là một trong những mô hình TTS mã nguồn mở đáng cài đặt nhất 2026. Sự kết hợp giữa 30 ngôn ngữ multilingual, voice design từ mô tả văn bản, voice cloning chất lượng cao, output 48kHz studio, và license Apache-2.0 cho thương mại – khiến nó trở thành replacement đáng tin cậy cho ElevenLabs trong rất nhiều use case. Đối với indie hacker, developer làm voice assistant, team làm audiobook/podcast/game – đây là công cụ giảm đáng kể chi phí mà vẫn giữ được chất lượng.