Tóm tắt nhanh:
LocalAI là AI engine mã nguồn mở để chạy LLM, giọng nói, hình ảnh và nhiều backend AI qua một API cục bộ. Nếu bạn muốn tự host AI thay vì phụ thuộc hoàn toàn vào cloud, cách thử nhanh nhất là chạy container Docker CPU trên cổng 8080, sau đó nạp model bằng lệnh local-ai run theo README chính thức. Bài này chỉ dùng các lệnh có trong nguồn chính thức và không giả vờ đã benchmark thực tế.
LocalAI là một AI engine mã nguồn mở từ repo mudler/LocalAI. README chính thức mô tả nó có thể chạy LLM, vision, voice, image và video trên nhiều loại phần cứng, với mục tiêu không bắt buộc phải có GPU cho bước dùng cơ bản.
Điểm đáng chú ý là LocalAI không cố đóng gói mọi thứ thành một cục khổng lồ. README nói các backend như llama.cpp, vLLM, whisper.cpp, stable-diffusion và MLX được tách riêng, chỉ kéo về khi model cần. Với người tự host, cách này giúp bạn bắt đầu nhỏ trước rồi mở rộng sau.
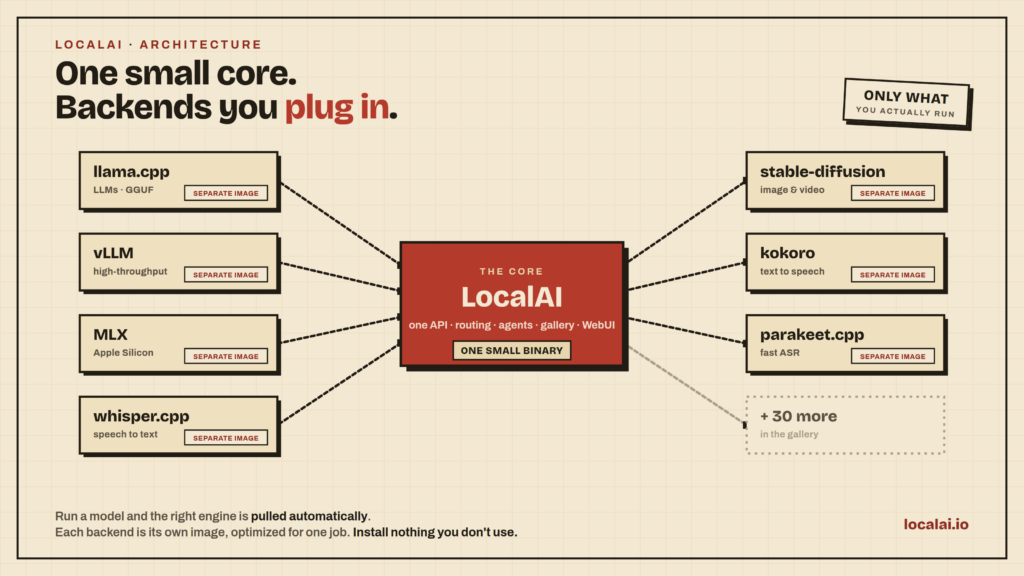
Khi nào bạn nên dùng LocalAI?
Bạn nên cân nhắc LocalAI khi muốn thử một API AI chạy trong máy hoặc server riêng, cần gom nhiều loại backend AI vào một điểm truy cập, hoặc muốn dựng môi trường lab cho LLM, speech-to-text, text-to-image mà vẫn giữ quyền kiểm soát dữ liệu.
Bạn chưa nên dùng nó như một hệ thống production nếu chưa đọc kỹ tài liệu triển khai, giới hạn phần cứng, cách quản lý model, bảo mật API và cập nhật backend. Bài này hướng dẫn mức khởi động an toàn, không thay thế tài liệu vận hành chính thức.
Cần chuẩn bị gì trước khi cài
Bạn cần Docker hoặc Podman nếu đi theo hướng container. Nếu dùng GPU, bạn phải chọn đúng image theo phần cứng: NVIDIA CUDA 12/13, AMD ROCm, Intel oneAPI, Vulkan hoặc Jetson theo README. Nếu chỉ muốn thử, CPU-only là đường đơn giản nhất.
Với macOS, README có file DMG nhưng cũng ghi rõ DMG chưa được Apple ký. Sau khi cài, nguồn chính thức yêu cầu chạy lệnh gỡ quarantine cho app nếu cần mở ứng dụng.
Cách cài LocalAI bằng Docker CPU
Lệnh quickstart CPU trong README chính thức là:
docker run -ti --name local-ai -p 8080:8080 localai/localai:latestNếu bạn đã từng chạy container này trước đó, README gợi ý khởi động lại bằng:
docker start -i local-aiSau khi container chạy, LocalAI lắng nghe qua cổng 8080 trên máy host. Nếu cổng 8080 đã bị chiếm, bạn cần đổi mapping cổng Docker theo nhu cầu của server.
Cách chạy với GPU theo README
Nếu có NVIDIA GPU và Docker đã hỗ trợ GPU, README đưa ra ví dụ CUDA 13 và CUDA 12:
docker run -ti --name local-ai -p 8080:8080 --gpus all localai/localai:latest-gpu-nvidia-cuda-13docker run -ti --name local-ai -p 8080:8080 --gpus all localai/localai:latest-gpu-nvidia-cuda-12Với AMD ROCm, ví dụ chính thức là:
docker run -ti --name local-ai -p 8080:8080 --device=/dev/kfd --device=/dev/dri --group-add=video localai/localai:latest-gpu-hipblasĐừng copy lệnh GPU nếu bạn chưa chắc driver, runtime Docker và quyền truy cập device đã đúng. Sai runtime GPU thường làm container chạy nhưng backend không tăng tốc như mong muốn.
Cách nạp model cơ bản
README chính thức đưa nhiều kiểu nguồn model. Ví dụ từ model gallery:
local-ai run llama-3.2-1b-instruct:q4_k_mTừ Hugging Face:
local-ai run huggingface://TheBloke/phi-2-GGUF/phi-2.Q8_0.ggufTừ Ollama OCI registry:
local-ai run ollama://gemma:2bBạn cũng có thể dùng YAML config hoặc OCI image theo ví dụ trong README, nhưng nên bắt đầu bằng model nhỏ để kiểm tra tài nguyên trước.
Cách kiểm tra sau khi chạy
Mình sẽ kiểm tra theo thứ tự: container còn chạy, cổng 8080 đã mở, log không báo lỗi backend, và model đã được kéo về thành công. Nếu bạn chạy lệnh local-ai run, hãy xem log tải model và lỗi thiếu backend trước khi kết luận LocalAI hỏng.
Một cách thực tế là mở tài liệu LocalAI và dùng đúng endpoint/API mà phiên bản bạn đang chạy hỗ trợ. Bài này không chèn endpoint tự suy đoán vì nguồn README quickstart trong lần kiểm tra chủ yếu xác nhận lệnh container và lệnh nạp model.
Lỗi thường gặp
Lỗi đầu tiên là cổng 8080 bị chiếm. Hãy đổi phần -p 8080:8080 sang cổng host khác nếu server đã có dịch vụ dùng 8080.
Lỗi thứ hai là dùng sai image GPU. NVIDIA CUDA 12, CUDA 13, Jetson, AMD ROCm và Intel GPU có image hoặc tham số khác nhau. Hãy chọn đúng theo README thay vì đoán.
Lỗi thứ ba là model quá nặng so với RAM/VRAM. Bắt đầu bằng model nhỏ, sau đó mới tăng kích thước.
Lưu ý an toàn và pháp lý
Nếu bạn tự host AI để xử lý dữ liệu khách hàng, hãy kiểm tra quyền truy cập API, log, vị trí lưu model và chính sách dữ liệu. Với model tải từ Hugging Face hoặc registry khác, bạn cần tự đọc license của từng model; license MIT của LocalAI không tự động áp dụng cho mọi model bạn tải về.
FAQ
LocalAI có bắt buộc GPU không?
Không cho bước thử cơ bản. README nói có thể chạy không cần GPU, nhưng tốc độ và khả năng chạy model lớn phụ thuộc phần cứng.
LocalAI có giống Ollama không?
LocalAI và Ollama đều liên quan chạy model cục bộ, nhưng LocalAI nhấn mạnh engine/API mã nguồn mở với nhiều backend như llama.cpp, vLLM, whisper.cpp, diffusers và MLX.
Có nên dùng ngay cho production không?
Chỉ nên sau khi bạn đã test tài nguyên, bảo mật API, cập nhật backend, giám sát log và license model. Bài này là hướng dẫn bắt đầu, không phải checklist production đầy đủ.