Tóm tắt nhanh:
- Headroom là một lớp tối ưu ngữ cảnh (context optimization layer) đặt giữa AI agent/ứng dụng LLM và provider, tự động nén log, tool output, file, RAG chunk, code… giúp giảm 60-95% token nhưng vẫn giữ nguyên độ chính xác câu trả lời.
- Bạn có thể dùng Headroom như thư viện Python/TypeScript, proxy “zero code change” hoặc tích hợp trực tiếp với LangChain, Agno và nhiều framework LLM khác, rất phù hợp với dev đang chạy AI agent dài, debugging log lớn hoặc làm RAG nặng.
Headroom là một dự án mã nguồn mở do Tejas Chopra phát triển, được mô tả như “context optimization layer for LLM applications”.
Nó ngồi giữa ứng dụng/AI agent của bạn và API LLM, chặn toàn bộ context (tool outputs, file, log, RAG chunks, lịch sử hội thoại…) rồi nén thông minh trước khi gửi lên model.
Dự án cung cấp nhiều “mode”: thư viện Python/TypeScript, proxy trong suốt, server MCP và các integration với framework như LangChain, Agno, Strands hay Vercel AI SDK.
Mục tiêu là giữ nguyên đáp án nhưng giảm mạnh số token bị đốt, từ đó giảm chi phí và tăng tốc độ phản hồi trên những workload dài, nhiều tool.

Tại sao nên dùng Headroom cho AI agent và LLM?
Khi bạn build agent with nhiều tool (code search, DB, RAG, log…), phần lớn token lại đến từ output dài dòng, lặp lại, và log “noise”.
Headroom giải quyết vấn đề này bằng cách nén bớt phần dư thừa, giữ lại signal quan trọng (error, boundary, summary…) để model vẫn reasoning tốt nhưng bạn chỉ trả tiền cho phần context thực sự cần thiết.
Theo README và tài liệu, Headroom thường giảm 60-95% token trên các workload thực tế như code search, incident debugging và GitHub issue triage, trong khi các benchmark như GSM8K hay TruthfulQA cho thấy độ chính xác giữ nguyên hoặc thậm chí cải thiện nhẹ.
Với dev chạy Claude Code, Cursor, Copilot CLI, LangChain agent hoặc workflow RAG dài hơi, mức tiết kiệm kiểu này là cực kỳ đáng kể về chi phí lẫn latency.
Cách Headroom hoạt động
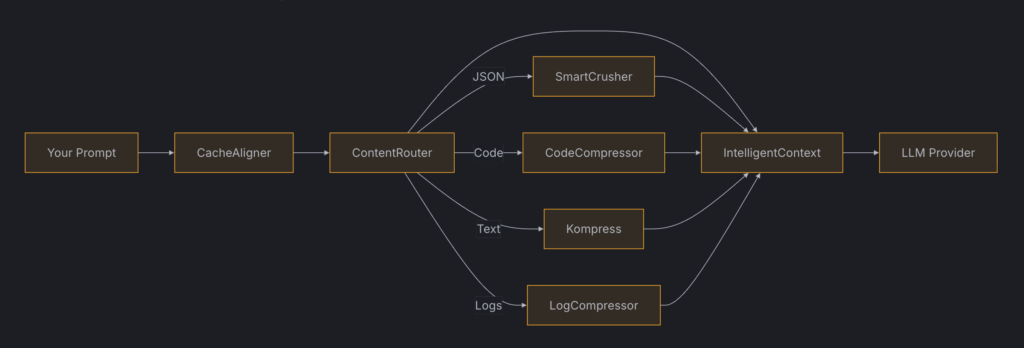
Về mặt kiến trúc, Headroom có một pipeline gồm các thành phần như ContentRouter, SmartCrusher, CodeCompressor, Kompress-base, CacheAligner và CCR (Compress‑Cache‑Retrieve).
ContentRouter tự động nhận diện loại nội dung (JSON, code, log, plain text, diff…) rồi đẩy sang compressor phù hợp để giảm kích thước nhưng vẫn bảo toàn cấu trúc quan trọng.
SmartCrusher xử lý JSON/tool output với cách nén mang tính thống kê, giữ lại lỗi, biên, anomaly; CodeCompressor dùng AST để nén code của nhiều ngôn ngữ như Python, JS, Go, Rust, Java, C++.
Kompress-base là model HuggingFace được train trên trace của agent, tối ưu cho prose và doc; CacheAligner giúp ổn định prefix prompt để tăng tỷ lệ hit cache của provider như Anthropic/OpenAI.
Điểm khác biệt: CCR và cross-agent memory
Một điểm đáng chú ý là cơ chế CCR (Compress‑Cache‑Retrieve), cho phép Headroom nén rất mạnh nhưng vẫn lưu bản gốc cục bộ, để LLM có thể gọi tool headroom_retrieve khi cần chi tiết đầy đủ.
Điều này biến pipeline trở thành “reversible compression”: trên dòng chảy chính bạn gửi bản nén, nhưng không mất dữ liệu vì vẫn có kênh truy xuất nguyên bản khi thật sự cần.
Bên cạnh đó, Headroom cung cấp một lớp “cross‑agent memory” – bộ nhớ dùng chung giữa nhiều agent/IDE như Claude Code, Codex, Gemini… với tự động dedup.
Nhờ vậy, các phiên làm việc dài ngày có thể chia sẻ context mà không cần spam token lặp lại giữa các tool hoặc agent khác nhau.
Headroom phù hợp với những ai?
Headroom đặc biệt hợp với các nhóm use case sau:
- Dev chạy AI coding agent hàng ngày (Claude Code, Cursor, Copilot CLI, Aider…).
- Team phải debug log build/test cực dài, incident SRE, log pipeline phức tạp.
- Hệ thống RAG với nhiều chunk lớn, kết quả search dài, issue triage ở quy mô GitHub/project lớn.
Nếu bạn chỉ dùng mỗi UI của một provider với context nhỏ, hoặc môi trường sandbox không cho chạy process cục bộ, lợi ích của Headroom sẽ hạn chế hơn.
Cài đặt Headroom bằng proxy (zero code change)
Cách nhanh nhất để thử Headroom là chạy nó như một proxy trong suốt.
Cài đặt proxy Headroom
Yêu cầu Python tối thiểu là 3.10. Sau đó, bạn cài proxy như sau:
pip install "headroom-ai[proxy]"
headroom proxy --port 8787Lệnh trên sẽ khởi chạy một server local ở port 8787, lắng nghe request theo API OpenAI‑compatible hoặc Anthropic‑style tùy config của bạn.
Từ đây, bạn chỉ cần trỏ client/agent sang proxy mà không sửa code business.
Ví dụ cho Claude hoặc bất kỳ client OpenAI‑compatible:
# Claude Code
ANTHROPIC_BASE_URL=http://localhost:8787 claude
# Client OpenAI-compatible (ví dụ Cursor)
OPENAI_BASE_URL=http://localhost:8787/v1 cursorToàn bộ prompt, tool output, log… sẽ đi qua Headroom trước khi tới provider, nên bạn có ngay p95 tiết kiệm token mà không cần “refactor” lại code.
Dùng Headroom như thư viện Python
Nếu bạn đang build backend Python với LLM (FastAPI, Django, Flask, worker…), bạn có thể cài SDK cơ bản:
pip install headroom-aiSau đó wrap model của bạn bằng compress() hoặc integration sẵn có.
Tích hợp Headroom với LangChain
Headroom có gói riêng cho LangChain:
pip install "headroom-ai[langchain]"Ví dụ dùng HeadroomChatModel để wrap ChatOpenAI:
from langchain_openai import ChatOpenAI
from headroom.integrations import HeadroomChatModel
base_llm = ChatOpenAI(model="gpt-4o")
llm = HeadroomChatModel(base_llm)
response = llm.invoke("Xin chào Headroom!")
print(response)Ở đây, Headroom sẽ tự động nén context mà LangChain gửi đi (bao gồm message, memory, retriever output…) trước khi tới model thật, nên bạn không cần tự viết logic “tóm tắt/nén” thủ công.
Tích hợp Headroom với Agno agent
Nếu bạn dùng framework Agno để build AI agent, có thể cài extension tương ứng:
pip install "headroom-ai[agno]"Đoạn code mẫu:
from agno.agent import Agent
from agno.models.openai import OpenAIChat
from headroom.integrations.agno import HeadroomAgnoModel
model = HeadroomAgnoModel(OpenAIChat(id="gpt-4o"))
agent = Agent(model=model)
result = agent.run("Phân tích log build này giúp tôi")
print(result)Headroom sẽ ngồi giữa Agno và OpenAI‑compatible API, tối ưu context cho toàn bộ phiên làm việc.
Dùng Headroom với Node/TypeScript hoặc frontend tooling
Ngoài Python, Headroom còn có SDK cho Node/TypeScript:
npm install headroom-aiBạn có thể gọi compress() ở layer API server Node, hoặc tích hợp vào tool CLI/custom agent viết bằng TypeScript.
Headroom cũng hỗ trợ qua các integration cho Vercel AI SDK, LiteLLM, MCP… giúp bạn giữ nguyên phần lớn code hiện tại.
Những lưu ý khi triển khai thực tế
Để đưa Headroom vào production hoặc môi trường tự host, bạn nên chú ý vài điểm sau:
- Tài nguyên máy chủ: Headroom chạy local, dùng thêm CPU/RAM để nén; đổi lại bạn tiết kiệm chi phí LLM side.
- Giám sát & metric: Headroom có endpoint Prometheus, log chi tiết, thống kê chi phí/token để bạn đo được ROI rõ ràng.
- Bảo mật & dữ liệu: Vì dữ liệu đi qua Headroom cục bộ, nó phù hợp với bối cảnh self‑hosted hoặc môi trường cần giữ dữ liệu on‑prem.
Đối với mô hình business như website, app SaaS hoặc workflow nội bộ, việc giảm 50-90% chi phí LLM mà không đụng vào logic ứng dụng thường mang lại biên lợi nhuận rất tốt.