Autodata là gì? Vì sao nó có thể thay đổi cách chúng ta tạo dữ liệu cho AI?
Trong vài năm qua, một sự thật ngày càng rõ hơn trong thế giới AI là: mô hình tốt không chỉ đến từ kiến trúc tốt hay nhiều GPU hơn, mà còn đến từ dữ liệu tốt hơn. Khi nguồn dữ liệu do con người viết trở nên đắt đỏ, chậm, và khó bao phủ hết các tình huống dài đuôi, synthetic data đã trở thành một hướng đi rất quan trọng.
Nhưng synthetic data cũng có một vấn đề lớn: làm sao biết dữ liệu được sinh ra thực sự chất lượng?
Đó là chỗ mà Autodata xuất hiện. Trong bài viết từ nhóm RAM @ Meta AI, Autodata được mô tả như một framework để AI agent đóng vai “data scientist tự động”: không chỉ sinh dữ liệu, mà còn tự đánh giá, rút kinh nghiệm, cải tiến quy trình, và thậm chí tối ưu chính bản thân agent đó để tạo dữ liệu ngày càng tốt hơn.
Nói ngắn gọn: Autodata không xem việc tạo dữ liệu là một lần prompt rồi xong. Nó xem đó là một vòng lặp nghiên cứu dữ liệu.
Từ Self-Instruct đến Autodata
Để hiểu Autodata, cần nhìn lại một cột mốc trước đó: Self-Instruct.
Self-Instruct cho thấy một mô hình ngôn ngữ có thể tự sinh instruction, input và output, sau đó lọc lại để dùng làm dữ liệu fine-tune cho chính nó. Đây là một bước tiến lớn vì nó giảm phụ thuộc vào dữ liệu gán nhãn thủ công.
Sau đó, cộng đồng mở rộng theo nhiều hướng:
- Grounded Self-Instruct: bám vào tài liệu hoặc nguồn tri thức cụ thể để giảm hallucination.
- CoT Self-Instruct: dùng chain-of-thought để sinh bài toán reasoning phức tạp hơn.
- Self-Challenging: cho agent tương tác với tool và cố tình tạo task khó hơn.
Tuy nhiên, theo bài blog của Meta, phần lớn các hướng này vẫn có một giới hạn: chúng cải thiện dữ liệu bằng cách sinh nhiều hơn, lọc tốt hơn, hoặc refine cục bộ hơn, nhưng chưa trực tiếp vận hành như một quy trình kiểm soát chất lượng dữ liệu đầu-cuối.
Autodata muốn đi xa hơn thế.
Autodata hoạt động như thế nào?
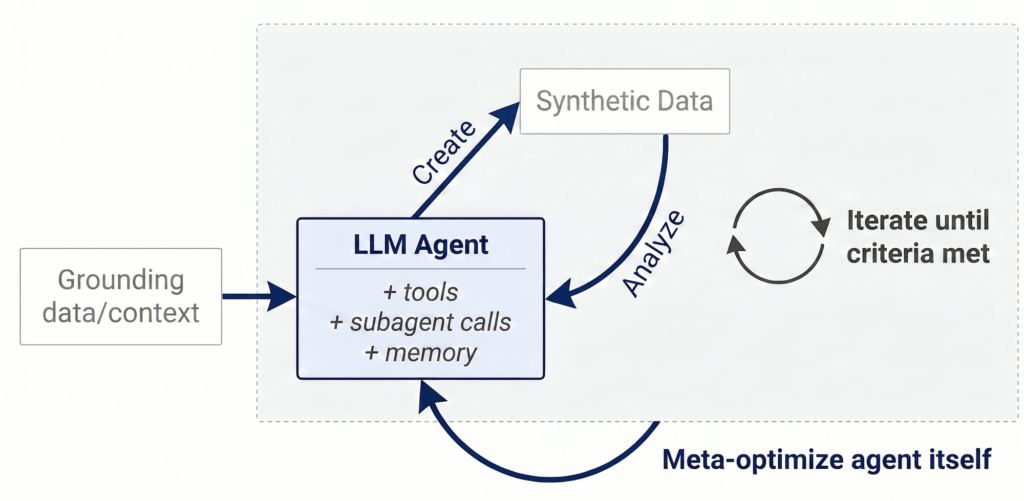
Ý tưởng cốt lõi của Autodata là giao cho một AI agent vai trò của một nhà khoa học dữ liệu.
Một data scientist giỏi không chỉ tạo dataset. Họ sẽ làm ít nhất 4 việc:
- Tạo dữ liệu ban đầu.
- Soi lại dữ liệu xem có đúng, có khó, có đa dạng, có hữu ích không.
- Rút ra bài học từ những lỗi và điểm yếu.
- Cập nhật “recipe” tạo dữ liệu rồi chạy tiếp vòng mới.
Autodata biến đúng quy trình đó thành một loop cho agent.
1. Data creation: tạo dữ liệu
Main agent bám vào một nguồn cụ thể như tài liệu toán, luật, code, hay paper nghiên cứu để sinh ra dữ liệu huấn luyện hoặc dữ liệu đánh giá. Quan trọng là agent không bị giới hạn ở một prompt cố định; nó có thể dùng thêm tool, skill, inference-time compute, hoặc các kinh nghiệm học được từ các vòng trước.
2. Data analysis: phân tích dữ liệu
Sau khi tạo dữ liệu, agent không dừng ở bước “xong rồi”. Nó sẽ kiểm tra:
- Ví dụ có đúng không?
- Có đủ khó không?
- Có thực sự phân biệt được mô hình mạnh và yếu không?
- Dataset có bị lặp ý, lệch phân phối, hoặc thiếu đa dạng không?
Từ đó, agent rút ra learnings để sửa cách sinh dữ liệu ở vòng sau.
3. Lặp đến khi dữ liệu đủ tốt
Toàn bộ quá trình tạo dữ liệu và phân tích dữ liệu được lặp lại nhiều lần cho đến khi đạt tiêu chí dừng. Đây là phần khiến Autodata giống một quy trình nghiên cứu thực thụ hơn là một script sinh dữ liệu hàng loạt.
4. Meta-optimization: tối ưu chính “nhà khoa học dữ liệu”
Điểm thú vị nhất của Autodata là nó không chỉ tối ưu dataset, mà còn tối ưu agent đang tạo dataset.
Nói cách khác, nếu quy trình hiện tại của agent chưa đủ tốt, ta có thể đánh giá, sửa scaffold, sửa harness, thay đổi logic điều phối, rồi đo lại xem khả năng tạo dữ liệu có tăng lên không. Bài blog gọi đây là outer loop, còn quá trình tạo và chấm dữ liệu là inner loop.
Đây là một ý tưởng rất mạnh: thay vì chỉ hỏi “mẫu dữ liệu này tốt không?”, ta còn hỏi “quy trình sinh ra mẫu dữ liệu này có thể được cải tiến tự động không?”
Agentic Self-Instruct: phiên bản Autodata cụ thể đầu tiên
Để chứng minh ý tưởng, nhóm tác giả thử một instantiation cụ thể của Autodata có tên Agentic Self-Instruct.
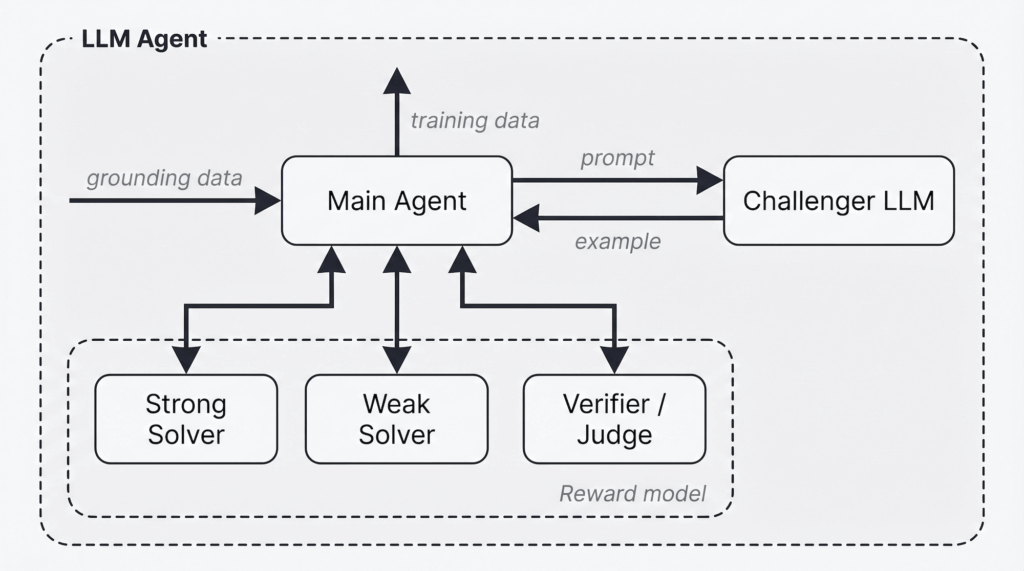
Trong thiết kế này, main agent điều phối 4 subagent:
- Challenger: tạo ví dụ huấn luyện.
- Weak solver: mô hình yếu, được kỳ vọng sẽ làm không tốt.
- Strong solver: mô hình mạnh hơn, được kỳ vọng sẽ làm tốt hơn.
- Judge/Verifier: chấm đầu ra theo rubric hoặc tiêu chí kiểm định.
Mục tiêu không phải là tạo ra bài toán mà ai cũng làm được. Mục tiêu là tạo ra bài toán mà:
- mô hình mạnh giải được,
- mô hình yếu làm kém,
- và khoảng cách giữa hai bên đủ rõ.
Đây là một thay đổi tư duy rất đáng chú ý.
Thay vì hỏi: “Dữ liệu này có hợp lệ không?”
Autodata hỏi thêm: “Dữ liệu này có đủ sức phân biệt năng lực reasoning thật sự không?”
Weak-vs-Strong gap: thước đo rất đáng chú ý
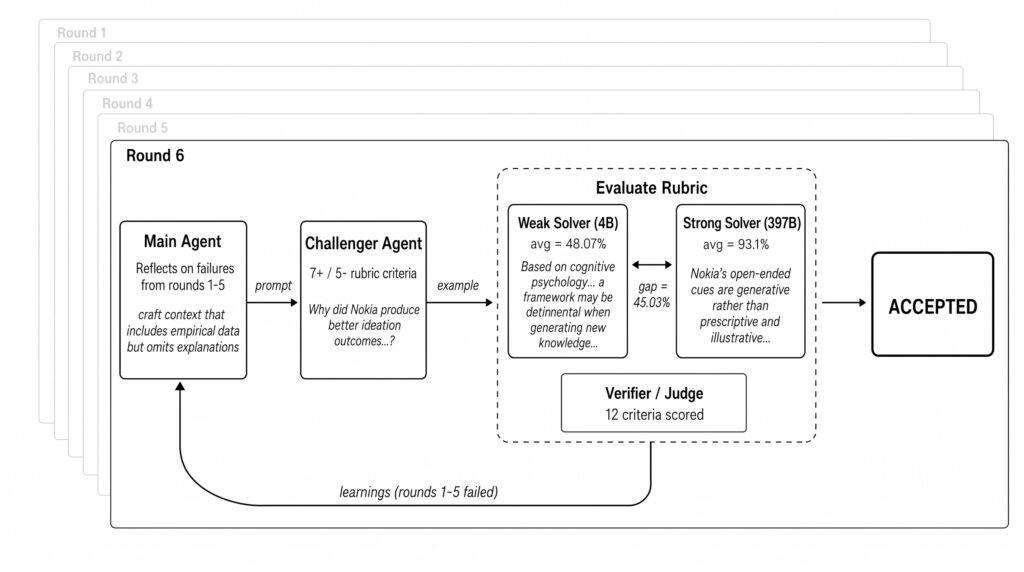
Trong bài blog, Agentic Self-Instruct được dùng để tạo câu hỏi nghiên cứu khoa học máy tính từ paper học thuật. Mỗi câu hỏi đi qua nhiều vòng:
- Challenger sinh câu hỏi, ngữ cảnh, đáp án tham chiếu và rubric.
- Quality verifier kiểm tra câu hỏi có ổn không.
- Weak solver và strong solver cùng làm bài.
- Judge chấm điểm theo rubric.
- Nếu khoảng cách weak/strong chưa đạt, agent phản hồi lại cho Challenger để sinh câu hỏi mới từ một góc khác.
Điểm hay ở đây là phản hồi không mơ hồ. Agent biết rõ câu hỏi trước đó thất bại vì:
- quá dễ,
- strong solver cũng làm không nổi,
- hoặc rubric/chất lượng câu hỏi có vấn đề.
Nhờ vậy, mỗi vòng lặp đều có hướng cải tiến cụ thể.
Kết quả: khác biệt không chỉ nhỏ, mà khá lớn
Theo số liệu được nêu trong bài blog:
- Với CoT Self-Instruct kiểu truyền thống, weak solver đạt 71.4%, strong solver đạt 73.3%, chênh lệch chỉ 1.9 điểm.
- Với Agentic Self-Instruct, weak solver giảm xuống 43.7%, strong solver tăng lên 77.8%, tạo ra khoảng cách 34 điểm.
Đây là một kết quả đáng chú ý vì nó cho thấy loop agentic không chỉ sinh ra dữ liệu “trông có vẻ hay”, mà sinh ra dữ liệu phân hóa năng lực mô hình tốt hơn hẳn.
Nói cách khác, nếu mục tiêu là huấn luyện hoặc benchmark reasoning, thì dữ liệu kiểu này có giá trị hơn nhiều so với dữ liệu được sinh một phát rồi lọc nhẹ.
Tác động đến huấn luyện mô hình
Bài blog còn đi thêm một bước nữa: dùng dữ liệu từ Agentic Self-Instruct để huấn luyện Qwen-3.5-4B và so với dữ liệu từ CoT Self-Instruct.
Kết luận được báo cáo là mô hình huấn luyện trên dữ liệu Agentic Self-Instruct cho hiệu quả tốt hơn. Điều này quan trọng vì nó xác nhận một điều rất thực tế:
Dữ liệu khó hơn, có mục tiêu rõ hơn, và phân biệt năng lực tốt hơn có thể chuyển thành năng lực reasoning tốt hơn sau huấn luyện.
Nếu kết quả này tiếp tục được xác nhận ở nhiều domain khác, Autodata có thể trở thành một cách mới để biến compute ở giai đoạn inference thành giá trị ở giai đoạn training.
Meta-optimization: phần “đáng tiền” nhất của ý tưởng
Theo mình, phần hay nhất của Autodata không nằm ở chuyện dùng nhiều agent, mà nằm ở tầng meta-optimization.
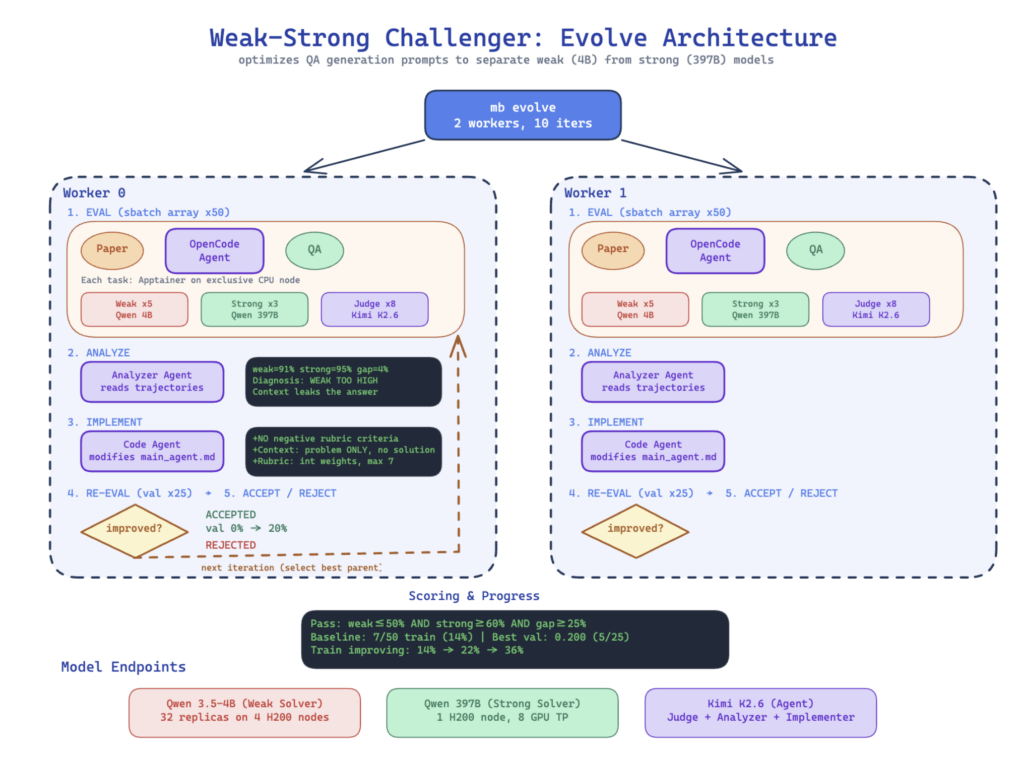
Tác giả mô tả một outer loop nơi scaffold của agent được xem như một đối tượng có thể tiến hóa:
- đánh giá harness hiện tại trên một batch tài liệu,
- phân tích các failure pattern,
- chỉnh lại code/scaffold,
- chạy lại trên validation,
- chỉ giữ thay đổi nếu nó làm tăng weak-strong separation rate.
Bài blog nêu một con số rất đáng chú ý: validation pass rate tăng từ 12.8% lên 42.4% qua nhiều vòng accepted iterations.
Nếu kết quả này bền vững, nó gợi mở một tương lai khá thú vị: không chỉ model được train, mà chính “quy trình tạo dữ liệu cho model” cũng trở thành đối tượng để train và tiến hóa.
Vì sao Autodata quan trọng với các team AI thực tế?
Autodata nghe có vẻ rất research, nhưng ý tưởng của nó lại cực kỳ thực dụng.
1. Tạo benchmark nội bộ tốt hơn
Nhiều team AI có một vấn đề chung: benchmark nội bộ quá dễ, quá lặp, hoặc không phản ánh lỗi thật trong sản phẩm. Một quy trình kiểu Autodata có thể giúp sinh ra các bộ eval khó hơn, sát domain hơn, và liên tục được cải tiến.
2. Tạo dữ liệu cho domain hẹp
Trong các bài toán như pháp lý, tài chính, y tế, vận hành doanh nghiệp, dữ liệu chuẩn thường ít và đắt. Nếu agent có grounding tốt trên tài liệu nội bộ, Autodata có thể là cách tạo synthetic data có chủ đích thay vì “prompt một lần rồi cầu may”.
3. Tối ưu cho khả năng reasoning thật sự
Nếu bạn chỉ tối ưu để mô hình trả lời trôi chảy, bạn dễ thu được dữ liệu đẹp bề mặt nhưng nông. Cách đo weak-vs-strong gap buộc hệ thống phải tìm ra những ví dụ thực sự đòi hỏi reasoning.
4. Biến inference compute thành training value
Đây có lẽ là luận điểm chiến lược nhất trong bài blog: khi có thêm compute ở thời điểm sinh dữ liệu, ta không nhất thiết phải dùng nó chỉ để trả lời người dùng tốt hơn ngay lập tức. Ta có thể dùng compute đó để tạo dữ liệu tốt hơn, rồi tái đầu tư vào vòng huấn luyện sau.
Nhưng cũng cần nhìn rõ giới hạn
Autodata rất hấp dẫn, nhưng chưa phải cây đũa thần.
Có ít nhất 4 lưu ý lớn.
1. Chất lượng objective quyết định chất lượng dữ liệu
Nếu rubric tệ, judge lệch, hoặc acceptance criteria sai, agent có thể tối ưu nhầm thứ cần tối ưu.
2. “Hack chỉ số” là rủi ro có thật
Khi dùng weak-vs-strong gap làm mục tiêu, hệ thống có thể vô tình học cách tạo các câu hỏi tối đa hóa gap nhưng không thực sự hữu ích cho sản phẩm hay người dùng.
3. Orchestration cost không rẻ
So với cách sinh dữ liệu một lần, một pipeline nhiều agent + verifier + solver + judge rõ ràng tốn inference hơn khá nhiều.
4. Grounding vẫn là nền móng
Nếu nguồn tài liệu đầu vào sai, thiếu, cũ hoặc nhiễu, thì dù vòng lặp có đẹp đến đâu, dữ liệu sinh ra vẫn có nguy cơ lệch.
Autodata đáng chú ý vì nó thay đổi cách ta nghĩ về synthetic data.
Thay vì xem dữ liệu là thứ được “đẻ ra” từ một prompt, Autodata xem dữ liệu là sản phẩm của một quy trình khoa học có phản hồi, có đo lường, có cải tiến, và có thể tự tối ưu.
Điểm mới không chỉ là “dùng agent để tạo dữ liệu”, mà là:
- dùng agent để đóng vai data scientist,
- dùng vòng lặp để kiểm soát chất lượng dữ liệu,
- và dùng meta-optimization để cải tiến chính quy trình tạo dữ liệu.
Nếu hướng đi này tiếp tục chứng minh được hiệu quả trên nhiều domain hơn, Autodata có thể trở thành một mảnh ghép quan trọng trong tương lai của AI: nơi compute không chỉ tạo ra câu trả lời tốt hơn, mà còn tạo ra dữ liệu tốt hơn để huấn luyện thế hệ mô hình tiếp theo.