Autoresearch: Khi AI agent tự trở thành nhà khoa học – 100 thí nghiệm LLM trong một đêm trên một GPU
Tóm tắt:
- Tự động hóa vòng lặp R&D hoàn toàn: Autoresearch giao quyền kiểm soát file
train.pycho AI agent – agent tự chỉnh sửa kiến trúc, siêu tham số, optimizer rồi huấn luyện, đánh giá và quyết định giữ hay bỏ kết quả mà không cần con người can thiệp.- Tối ưu hóa trên phần cứng hạn chế: Toàn bộ vòng lặp nghiên cứu chạy trên một GPU NVIDIA duy nhất, với mỗi thí nghiệm kéo dài đúng 5 phút – tương đương khoảng 100 thí nghiệm trong một đêm ngủ.
- Chỉ số đánh giá độc lập với kiến trúc: Metric
val_bpb(validation bits per byte) cho phép so sánh công bằng giữa các lần chạy với kiến trúc và kích thước từ vựng hoàn toàn khác nhau.- Con người lập trình ở cấp độ chỉ dẫn, không phải code: Thay vì chỉnh sửa Python, nhà nghiên cứu viết
program.mdbằng ngôn ngữ tự nhiên để định hướng chiến lược nghiên cứu cho agent.- Nền tảng mở rộng cho tương lai AI research: Dự án được Karpathy đặt trong bối cảnh dài hạn – một điểm khởi đầu có thể ghi nhận thế hệ thứ 10.205 của codebase trong tương lai tự cải tiến liên tục.
Bối cảnh: tại sao vòng lặp nghiên cứu thủ công đang trở nên lỗi thời
Quy trình nghiên cứu học máy truyền thống có một nút thắt cố hữu: con người phải ở giữa mỗi vòng lặp thử nghiệm. Một kỹ sư ML đọc kết quả, suy nghĩ về giả thuyết tiếp theo, chỉnh sửa code, chờ huấn luyện xong, rồi lại đọc kết quả. Với mỗi thí nghiệm kéo dài từ vài giờ đến vài ngày, tốc độ tiến triển bị giới hạn bởi thời gian sinh học của người nghiên cứu.
Andrej Karpathy – cựu Giám đốc AI của Tesla và là một trong những tác giả có ảnh hưởng nhất trong cộng đồng AI mã nguồn mở – đã đặt câu hỏi: điều gì xảy ra nếu ta trao toàn bộ vòng lặp đó cho một AI agent, giữ thời gian mỗi thí nghiệm ở mức 5 phút, và để agent chạy suốt đêm?
Kết quả là Autoresearch – một hệ thống tối giản nhưng đầy đủ chức năng, nơi AI agent thực sự đóng vai nhà khoa học: quan sát, giả thuyết, thử nghiệm, ghi chép, và lặp lại.
Kiến trúc của Autoresearch: ba file, một vòng lặp
Triết lý thiết kế tối giản
Toàn bộ repo chỉ gồm ba file có ý nghĩa thực sự, và đây là lựa chọn có chủ đích:
prepare.py– File cố định, không bao giờ bị agent chỉnh sửa. Chứa các hằng số hệ thống, logic chuẩn bị dữ liệu (tải tập huấn luyện, huấn luyện BPE tokenizer), dataloader và hàm đánh giá.train.py– File duy nhất agent được phép chỉnh sửa. Chứa toàn bộ định nghĩa mô hình GPT, optimizer kép (Muon + AdamW), và vòng lặp huấn luyện. Mọi thứ trong file này đều là đối tượng thử nghiệm: kiến trúc transformer, siêu tham số, chiến lược batch, lịch trình learning rate.program.md– Tài liệu chỉ dẫn cho agent, viết bằng ngôn ngữ tự nhiên. Đây là nơi con người “lập trình” ở cấp độ chiến lược thay vì cú pháp. File này được nhà nghiên cứu chỉnh sửa và tinh chỉnh theo thời gian.
Sự phân tách này có ý nghĩa sâu sắc: bằng cách giới hạn agent chỉ trong một file duy nhất, mọi thay đổi đều có thể xem xét lại qua diff, và phạm vi tác động luôn kiểm soát được.
Vòng lặp tự trị của agent
Cơ chế hoạt động cốt lõi diễn ra theo trình tự sau:
- Agent đọc
program.mdđể hiểu mục tiêu và ràng buộc nghiên cứu hiện tại. - Agent phân tích lịch sử thí nghiệm từ các git commit trước đó.
- Agent đề xuất và thực hiện sửa đổi vào
train.py– có thể là thay đổi kiến trúc, điều chỉnh batch size, thử nghiệm window pattern mới. - Hệ thống chạy huấn luyện trong đúng 5 phút thực (wall clock time), không phụ thuộc vào cấu hình phần cứng.
- Sau khi huấn luyện, chỉ số
val_bpbđược tính toán và so sánh với kết quả tốt nhất trước đó. - Nếu cải thiện: agent commit thay đổi vào nhánh git feature với mô tả thử nghiệm. Nếu không: agent revert và ghi chú kết luận.
- Vòng lặp bắt đầu lại từ bước 2.
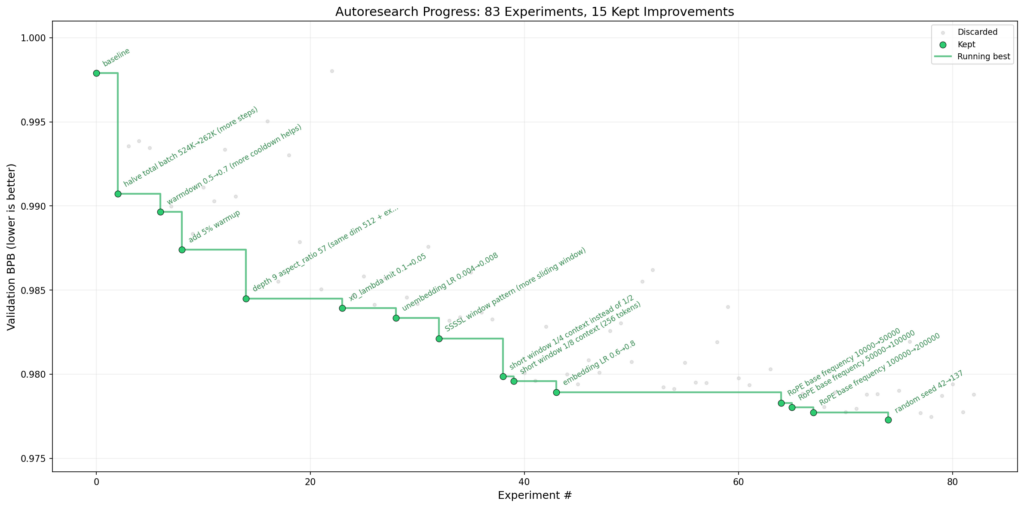
Trên phần cứng H100, chu kỳ này mang lại khoảng 12 thí nghiệm mỗi giờ, tức gần 100 thí nghiệm trong một đêm – một tốc độ không thể đạt được với quy trình thủ công.
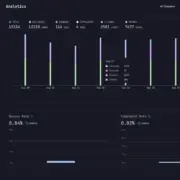
Val_bpb – chỉ số công bằng cho mọi kiến trúc
Lựa chọn val_bpb (validation bits per byte) làm chỉ số duy nhất là một quyết định kỹ thuật thông minh. Không giống cross-entropy loss thông thường bị ảnh hưởng bởi kích thước từ vựng, val_bpb là đơn vị độc lập với tokenizer và vocab size. Điều này có nghĩa là khi agent thử nghiệm một kiến trúc với từ vựng 4.096 token hay 16.384 token, kết quả vẫn có thể so sánh trực tiếp. Giá trị thấp hơn luôn có nghĩa là mô hình tốt hơn, bất kể cấu hình cụ thể.
Nền tảng kỹ thuật: nanochat và optimizer Muon
Nanochat – phòng thí nghiệm LLM thu nhỏ
Autoresearch xây dựng trên nền tảng của nanochat – dự án huấn luyện LLM tối giản nhất mà Karpathy từng công bố. Nanochat bao phủ toàn bộ vòng đời của một LLM: tokenization, pretraining, finetuning, evaluation và inference, tất cả trong một codebase có thể đọc và hiểu hoàn toàn.
Thiết kế của nanochat xoay quanh một tham số duy nhất: DEPTH – chiều sâu của transformer. Từ tham số này, toàn bộ các siêu tham số còn lại (chiều rộng, số head, learning rate, batch size) được tự động tính toán theo nguyên tắc compute-optimal scaling. Đây là lý do agent có thể thử nghiệm “thay đổi kiến trúc” một cách an toàn mà không tạo ra các cấu hình lệch chuẩn.
Optimizer kép: Muon kết hợp AdamW
train.py sử dụng tổ hợp hai optimizer: AdamW cho các tham số embedding và các lớp không thuần túy tuyến tính, và Muon (Momentum + Orthogonalization Update Norm) cho các lớp tuyến tính trong transformer. Muon là optimizer thế hệ mới, được thiết kế đặc biệt cho các ma trận trọng số của transformer, mang lại hội tụ nhanh hơn trong thực nghiệm. Sự kết hợp này là một trong những điểm agent có thể thử nghiệm và tối ưu hóa.
Hướng dẫn cài đặt và thiết lập môi trường
Yêu cầu hệ thống
- Một GPU NVIDIA (môi trường kiểm thử chính thức: H100; hỗ trợ GPU nhỏ hơn qua cấu hình tùy chỉnh).
- Python 3.10 trở lên.
- Công cụ quản lý dự án Python
uv.
Các bước cài đặt
Bước 1: Cài đặt uv nếu chưa có
curl -LsSf https://astral.sh/uv/install.sh | shuv là trình quản lý dự án Python hiện đại, thay thế cho pip + virtualenv với tốc độ cài đặt nhanh hơn đáng kể và quản lý dependency có tính tái lập cao hơn.
Bước 2: Clone repository và cài đặt phụ thuộc
git clone https://github.com/karpathy/autoresearch.git
cd autoresearch
uv syncLệnh uv sync đọc file pyproject.toml, tạo virtual environment và cài đặt đúng các phiên bản phụ thuộc đã được khóa. Không cần kích hoạt môi trường thủ công – uv run tự động sử dụng môi trường đã tạo.
Bước 3: Chuẩn bị dữ liệu và huấn luyện tokenizer
uv run prepare.pyLệnh này thực hiện hai công việc một lần: tải tập dữ liệu huấn luyện và huấn luyện BPE tokenizer với kích thước từ vựng mặc định 8.192 token. Quá trình mất khoảng 2 phút và chỉ cần chạy một lần duy nhất.
Bước 4: Xác minh thiết lập bằng cách chạy thủ công một thí nghiệm
uv run train.pyLệnh này chạy một chu kỳ huấn luyện đầy đủ trong đúng 5 phút. Nếu lệnh hoàn thành bình thường và in ra giá trị val_bpb, môi trường đã sẵn sàng cho chế độ nghiên cứu tự trị.
Kích hoạt chế độ nghiên cứu tự trị
Cấu hình program.md
File program.md mặc định trong repository là bộ khung tối thiểu có chủ đích. Karpathy thiết kế nó đơn giản để người dùng tự xây dựng “tổ chức nghiên cứu” của mình qua thời gian. Một program.md hiệu quả thường bao gồm:
- Mục tiêu nghiên cứu hiện tại: Ví dụ, “Tập trung tối ưu hóa attention mechanism” hoặc “Thử nghiệm các biến thể của learning rate schedule”.
- Ràng buộc cứng: Các tham số không được thay đổi để đảm bảo so sánh công bằng giữa các thí nghiệm.
- Hướng dẫn ghi chép: Cách agent nên mô tả thay đổi trong git commit message.
- Ưu tiên thử nghiệm: Danh sách các giả thuyết theo thứ tự ưu tiên mà agent nên khám phá.
Khởi động agent
Mở agent AI yêu thích (Claude, Codex, hoặc bất kỳ mô hình nào hỗ trợ tool calling) trong thư mục repository, vô hiệu hóa các quyền truy cập ngoài phạm vi cần thiết, rồi khởi động bằng lời nhắc:
Hi, have a look at program.md and let's kick off a new experiment! Let's do the setup first.Agent sẽ đọc program.md, kiểm tra lịch sử commit để hiểu trạng thái nghiên cứu hiện tại, đề xuất thay đổi đầu tiên vào train.py, thực thi thử nghiệm, và bắt đầu vòng lặp tự trị.
Theo dõi kết quả qua git log
Một đặc điểm thiết kế quan trọng: mỗi thí nghiệm thành công được ghi lại bằng một git commit với đầy đủ thông tin – giá trị val_bpb trước và sau, mô tả thay đổi, và lý do agent đưa ra quyết định đó. Buổi sáng hôm sau, nhà nghiên cứu có thể chạy git log để đọc toàn bộ “nhật ký thí nghiệm” qua đêm như đọc một báo cáo nghiên cứu.
Tùy chỉnh cho phần cứng nhỏ hơn
Đối với máy tính không có GPU H100 – MacBook, GPU tiêu dùng thông thường, hay GPU AMD – Karpathy đưa ra một bộ gợi ý điều chỉnh có thứ tự ưu tiên rõ ràng:
- Dùng tập dữ liệu entropy thấp hơn như TinyStories thay vì tập dữ liệu ngôn ngữ chung.
- Giảm
vocab_sizetừ 8.192 xuống 4.096 hoặc thấp hơn. - Hạ
MAX_SEQ_LENtrongprepare.py, đồng thời tăng nhẹDEVICE_BATCH_SIZEđể bù trừ số token mỗi bước. - Giảm
EVAL_TOKENSđể rút ngắn thời gian tính validation loss. - Hạ
DEPTHtừ 8 xuống 4 để thu nhỏ kích thước mô hình. - Chuyển
WINDOW_PATTERNsang"L"thuần túy thay vì"SSSL"(pattern chú ý băng tần có thể rất kém hiệu quả trên phần cứng nhỏ).
Cộng đồng cũng đã xây dựng các fork chuyên biệt: autoresearch-macos cho Apple Silicon, autoresearch-mlx tận dụng framework MLX của Apple, và autoresearch-win-rtx cho GPU RTX trên Windows.
Ý nghĩa rộng hơn: hướng đến tự động hóa R&D hoàn toàn
Autoresearch không chỉ là một công cụ tiện ích. Karpathy đặt nó trong một bối cảnh tự thuật lớn hơn: đây là “câu chuyện về cách tất cả bắt đầu” – điểm khởi đầu của một hành trình mà trong đó AI agent dần tiếp quản toàn bộ vòng lặp nghiên cứu khoa học.
Sự chuyển dịch căn bản mà dự án này đề xuất là: nhà nghiên cứu không còn viết code thí nghiệm, họ viết chỉ dẫn chiến lược cho agent. Kỹ năng cần thiết dịch chuyển từ thành thạo PyTorch sang khả năng tư duy về chiến lược nghiên cứu và soạn thảo program.md hiệu quả.
Trên một GPU duy nhất, với ba file và một agent AI, Autoresearch chứng minh rằng giới hạn thực sự của nghiên cứu học máy không còn là năng lực phần cứng – mà là tốc độ lặp lại thử nghiệm, và đó là thứ AI agent có thể đảm nhận hoàn toàn.
Tài liệu chính chủ cho anh em tham khảo thêm:
- Kho mã nguồn Autoresearch: https://github.com/karpathy/autoresearch
- Nanochat (nền tảng huấn luyện): https://github.com/karpathy/nanochat
- Demo trực tiếp và leaderboard: https://github.com/karpathy/nanochat#time-to-gpt-2-leaderboard
- Tweet gốc của Karpathy: https://x.com/karpathy/status/2030371219518931079