Bạn đang tìm kiếm một giải pháp kho dữ liệu (Data Warehouse) có khả năng phân tích dữ liệu lớn với tốc độ truy vấn dưới giây? Bạn muốn xây dựng các dashboard thời gian thực, thực hiện các truy vấn ad-hoc phức tạp mà không phải chờ đợi? Hãy cùng khám phá Apache Doris – một thế lực mới nổi trong thế giới dữ liệu lớn.
Bài viết này sẽ là kim chỉ nam toàn diện của bạn: từ việc giới thiệu Apache Doris là gì, hướng dẫn cài đặt self-hosted trên Ubuntu bằng Docker Compose, đến cách sử dụng cơ bản và một vài kỹ thuật nâng cao.
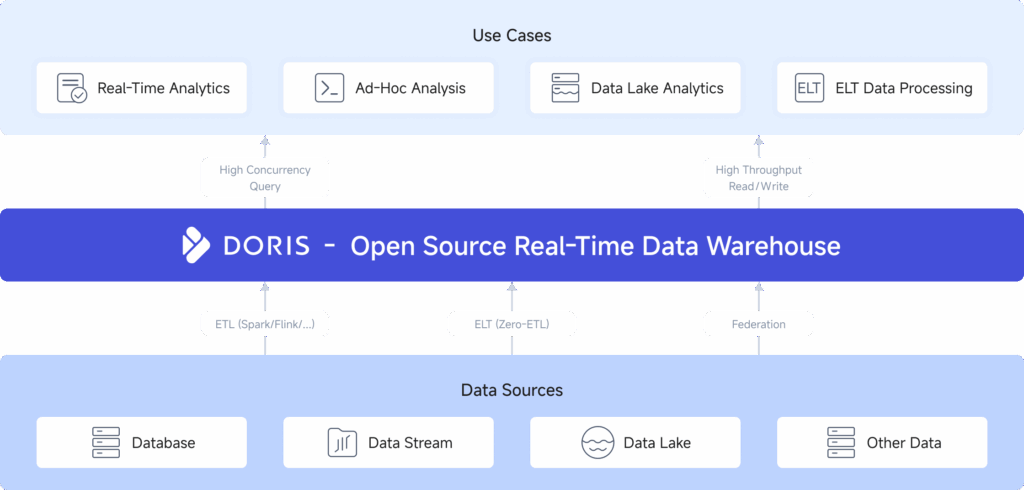
Apache Doris là gì? Tại sao bạn nên quan tâm?
Apache Doris là một kho dữ liệu phân tích thời gian thực (Real-time Analytical Data Warehouse) mã nguồn mở, dựa trên kiến trúc Xử lý Song song Hàng loạt (MPP). Nói một cách đơn giản, nó được thiết kế để lưu trữ và phân tích các tập dữ liệu khổng lồ (từ terabyte đến petabyte) và trả về kết quả truy vấn trong nháy mắt.
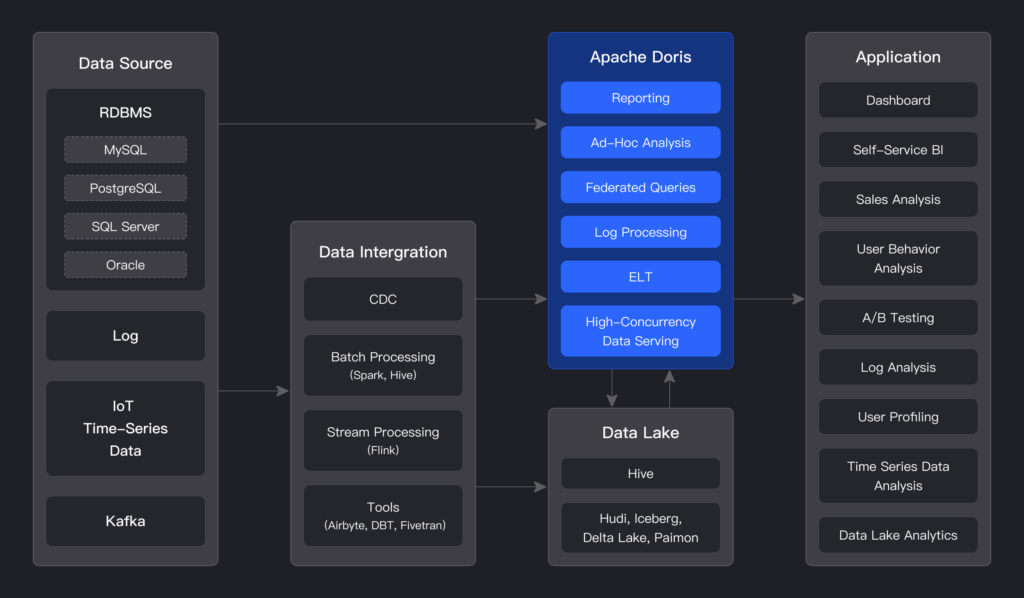
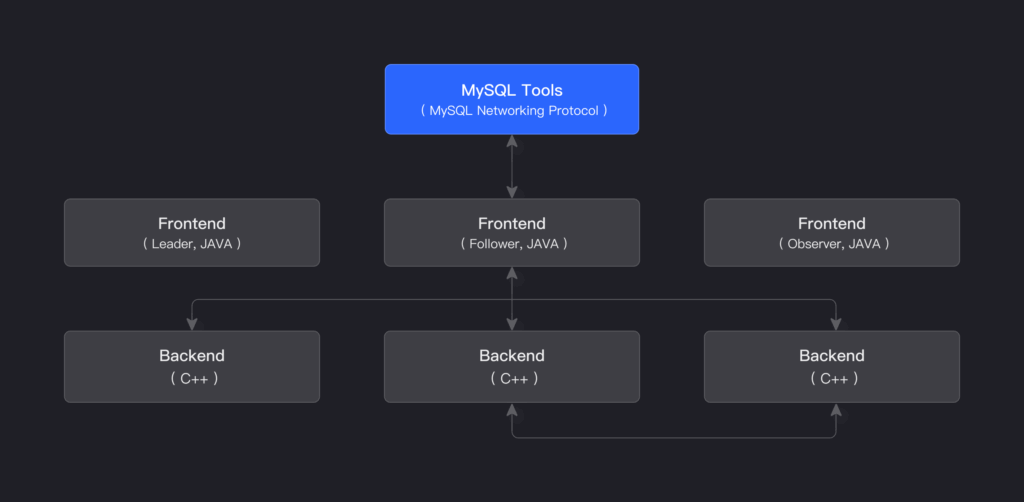
Kiến trúc cốt lõi
Điểm sáng giá nhất của Doris là kiến trúc cực kỳ đơn giản và gọn nhẹ, chỉ bao gồm hai thành phần chính:
- Frontend (FE): Đóng vai trò là “bộ não” của cụm, chịu trách nhiệm quản lý metadata, phân tích và lập kế hoạch truy vấn, cũng như xử lý kết nối từ client.
- Backend (BE): Là “cơ bắp” của cụm, chịu trách nhiệm lưu trữ dữ liệu vật lý và thực thi các mảnh truy vấn do FE gửi xuống.
Cả FE và BE đều có khả năng mở rộng theo chiều ngang một cách độc lập, giúp bạn dễ dàng nâng cấp hệ thống khi dữ liệu và khối lượng công việc tăng lên.
Các tính năng nổi bật
- Hiệu năng cực cao: Tận dụng công cụ thực thi vector hóa, lưu trữ dạng cột (columnar storage), và các chỉ mục thông minh để đạt tốc độ truy vấn dưới giây.
- Dễ sử dụng: Hoàn toàn tương thích với giao thức và cú pháp SQL của MySQL. Bạn có thể sử dụng các công cụ SQL client và BI quen thuộc (DBeaver, DataGrip, Superset, Metabase) để kết nối và làm việc với Doris.
- JOIN mạnh mẽ: Vượt trội so với nhiều hệ thống OLAP khác trong việc thực thi các truy vấn
JOINphức tạp giữa các bảng lớn. - Phân tích hợp nhất (Unified Analytics): Có khả năng truy vấn trực tiếp dữ liệu từ các nguồn bên ngoài như Hive, Iceberg, Hudi, MySQL, Elasticsearch mà không cần di chuyển dữ liệu.
Hướng dẫn cài đặt self-hosted bằng Docker Compose trên Ubuntu
Cách nhanh nhất và dễ dàng nhất để trải nghiệm Doris là triển khai bằng Docker. Hướng dẫn này sẽ giúp bạn thiết lập một cụm Doris cơ bản (1 FE và 1 BE) trên máy chủ Ubuntu.
Bước 1: Yêu cầu tiên quyết – Cài đặt Docker và Docker Compose
Trước tiên, hãy đảm bảo hệ thống của bạn đã được cập nhật và cài đặt các gói cần thiết.
sudo apt-get update
sudo apt-get install ca-certificates curl gnupgTiếp theo, thêm GPG key và repository chính thức của Docker.
# Thêm GPG key của Docker
sudo install -m 0755 -d /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
sudo chmod a+r /etc/apt/keyrings/docker.gpg
# Thêm repository vào sources.list
echo \
"deb [arch="$(dpkg --print-architecture)" signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu \
"$(. /etc/os-release && echo "$VERSION_CODENAME")" stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/nullCuối cùng, cài đặt Docker Engine và Docker Compose plugin.
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-pluginThêm người dùng hiện tại của bạn vào nhóm docker để có thể chạy lệnh docker mà không cần sudo (cần đăng xuất và đăng nhập lại để thay đổi có hiệu lực).
sudo usermod -aG docker $USER
newgrp dockerBước 2: Tạo tệp docker-compose.yml
Tạo một thư mục cho dự án Doris của bạn và tạo một tệp docker-compose.yml bên trong đó.
mkdir my-doris-cluster
cd my-doris-cluster
nano docker-compose.ymlDán nội dung sau vào tệp:
version: '3'
services:
doris-fe:
image: apache/doris:2.1.2-fe-x86_64
container_name: doris-fe-1
hostname: doris-fe-1
environment:
- FE_SERVERS=doris-fe-1:9010
- FE_ID=1
ports:
- "8030:8030" # Cổng HTTP cho UI
- "9030:9030" # Cổng query MySQL
volumes:
- ./fe/doris-meta:/opt/apache-doris/fe/doris-meta
- ./fe/log:/opt/apache-doris/fe/log
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8030"]
interval: 30s
timeout: 10s
retries: 3
doris-be:
image: apache/doris:2.1.2-be-x86_64
container_name: doris-be-1
hostname: doris-be-1
depends_on:
doris-fe:
condition: service_healthy
environment:
- FE_SERVERS=doris-fe-1:9010
- BE_ADDR=doris-be-1:9050
ports:
- "8040:8040" # Cổng HTTP cho BE
volumes:
- ./be/storage:/opt/apache-doris/be/storage
- ./be/log:/opt/apache-doris/be/logBước 3: Khởi chạy và xác minh cụm
Bây giờ, hãy khởi chạy cụm Doris của bạn ở chế độ nền.
docker compose up -dĐợi một vài phút để các container khởi động hoàn toàn. Bạn có thể kiểm tra trạng thái bằng lệnh:
docker compose psBạn sẽ thấy hai container doris-fe-1 và doris-be-1 đang ở trạng thái running (hoặc healthy).
Xác minh cài đặt:
- Giao diện Web: Mở trình duyệt và truy cập
http://<địa-chỉ-ip-máy-chủ>:8030. Bạn sẽ thấy giao diện quản trị của Doris. Đăng nhập với người dùngrootvà không cần mật khẩu. - MySQL Client: Kết nối tới Doris bằng bất kỳ công cụ SQL client nào (ví dụ: DBeaver, hoặc terminal
mysqlclient) với thông tin sau:- Host:
địa-chỉ-ip-máy-chủ - Port:
9030 - User:
root - Password: (để trống)
- Host:
Sau khi kết nối, chạy các lệnh sau để kiểm tra trạng thái của các node: SQLSHOW FRONTENDS; SHOW BACKENDS;
Bạn sẽ thấy Alive là true cho cả hai node FE và BE. Xin chúc mừng, cụm Apache Doris của bạn đã sẵn sàng!
Hướng dẫn sử dụng Apache Doris cơ bản
Bây giờ, hãy thực hiện một vài thao tác cơ bản để làm quen với Doris.
Bước 1: Tạo Cơ sở dữ liệu và Bảng
-- Tạo một cơ sở dữ liệu mới
CREATE DATABASE example_db;
-- Chuyển sang sử dụng cơ sở dữ liệu vừa tạo
USE example_db;
-- Tạo một bảng để lưu trữ dữ liệu bán hàng
-- Sử dụng mô hình Aggregate Key để tự động tổng hợp doanh thu theo ngày và sản phẩm
CREATE TABLE sales_records (
sale_date DATE,
product_id INT,
region VARCHAR(50),
revenue DECIMAL(10, 2)
)
AGGREGATE KEY(sale_date, product_id, region)
DISTRIBUTED BY HASH(product_id) BUCKETS 10
PROPERTIES (
"replication_num" = "1"
);Lưu ý về Mô hình Dữ liệu:
Doris hỗ trợ 3 mô hình chính:
- Aggregate Key: Tổng hợp các hàng có cùng key. Lý tưởng cho các báo cáo, dashboard.
- Unique Key: Đảm bảo tính duy nhất của key, các bản ghi mới sẽ ghi đè lên bản ghi cũ (upsert). Phù hợp cho dữ liệu cần cập nhật.
- Duplicate Key: Lưu trữ tất cả dữ liệu gốc, không tổng hợp. Phù hợp để lưu trữ chi tiết, truy vấn ad-hoc.
Bước 2: Nạp dữ liệu với Stream Load
Stream Load là phương thức phổ biến để nạp dữ liệu vào Doris qua HTTP. Tạo một tệp dữ liệu mẫu tên là sales_data.csv.
2025-07-01,101,North,1500.50
2025-07-01,102,North,800.00
2025-07-01,101,South,1200.75
2025-07-02,101,North,1600.00
2025-07-01,102,North,200.00Bây giờ, sử dụng curl để nạp tệp này vào bảng sales_records.
curl --location-trusted -u root: \
-H "column_separator:," \
-T sales_data.csv \
http://<địa-chỉ-ip-máy-chủ>:8030/api/example_db/sales_records/_stream_loadBạn sẽ nhận được một phản hồi JSON cho biết trạng thái nạp dữ liệu. Nếu Status là Success, dữ liệu đã được nạp thành công.
Bước 3: Truy vấn dữ liệu
Bây giờ là phần thú vị nhất! Hãy truy vấn dữ liệu bạn vừa nạp.
-- Xem tất cả dữ liệu
SELECT * FROM sales_records ORDER BY sale_date;
-- Lưu ý rằng Doris đã tự động tổng hợp doanh thu cho sản phẩm 102 ở khu vực North trong ngày 01-07
-- 800.00 + 200.00 = 1000.00
-- Tính tổng doanh thu theo ngày
SELECT sale_date, SUM(revenue) as total_revenue
FROM sales_records
GROUP BY sale_date
ORDER BY sale_date;
-- Tính tổng doanh thu theo khu vực
SELECT region, SUM(revenue) as total_revenue
FROM sales_records
GROUP BY region;Bạn sẽ thấy kết quả được trả về gần như ngay lập tức. Đây chính là sức mạnh của Apache Doris!
Các bước tiếp theo
Bài viết này chỉ là bước khởi đầu. Từ đây, bạn có thể khám phá các tính năng mạnh mẽ khác của Doris:
- Materialized Views: Tạo các view được tính toán trước để tăng tốc các truy vấn lặp lại.
- Scale-Out: Dễ dàng thêm các node BE mới vào cụm để tăng khả năng lưu trữ và xử lý.
- Backup & Restore: Sao lưu dữ liệu ra các kho lưu trữ như S3 và phục hồi khi cần.
- Tích hợp: Kết nối Doris với Apache Superset, Metabase để xây dựng dashboard, hoặc với Flink, Spark để xây dựng các pipeline dữ liệu thời gian thực.
Apache Doris là một công cụ cực kỳ mạnh mẽ, dễ tiếp cận và đang phát triển nhanh chóng. Hy vọng rằng qua bài hướng dẫn này, bạn đã có một khởi đầu thuận lợi để tự mình khám phá và xây dựng các ứng dụng phân tích dữ liệu hiệu năng cao. Chúc bạn thành công!