Cách chạy OpenClaw miễn phí với Gemma 4 và SearXNG
Nếu mục tiêu là dựng một AI agent chạy trên hạ tầng của riêng mình, không phải phụ thuộc hoàn toàn vào API thương mại, thì một cấu hình rất đáng cân nhắc là kết hợp OpenClaw, Ollama, Gemma 4 và SearXNG. Cấu trúc này cho phép chạy model cục bộ qua Ollama, dùng OpenClaw để điều phối agent và tool calling, đồng thời bổ sung web search tự host thông qua SearXNG.
Hệ thống này gồm những gì?
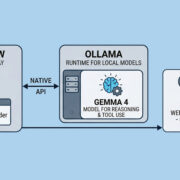
Có thể hình dung đơn giản như sau: OpenClaw là lớp agent và gateway, Ollama là runtime để chạy model local, Gemma 4 là họ model dùng để suy luận và gọi công cụ, còn SearXNG là công cụ tìm kiếm web tự host. OpenClaw hiện tích hợp trực tiếp với Ollama qua native API và hỗ trợ SearXNG như một web_search provider không cần API key.
Điểm hấp dẫn của cách làm này là bạn không chỉ có một chatbot local, mà có thể xây dựng một agent có khả năng làm việc nhiều bước: tìm kiếm thông tin, tóm tắt, đọc file, tạo nội dung, rồi tiếp tục chuyển kết quả sang các bước xử lý khác.
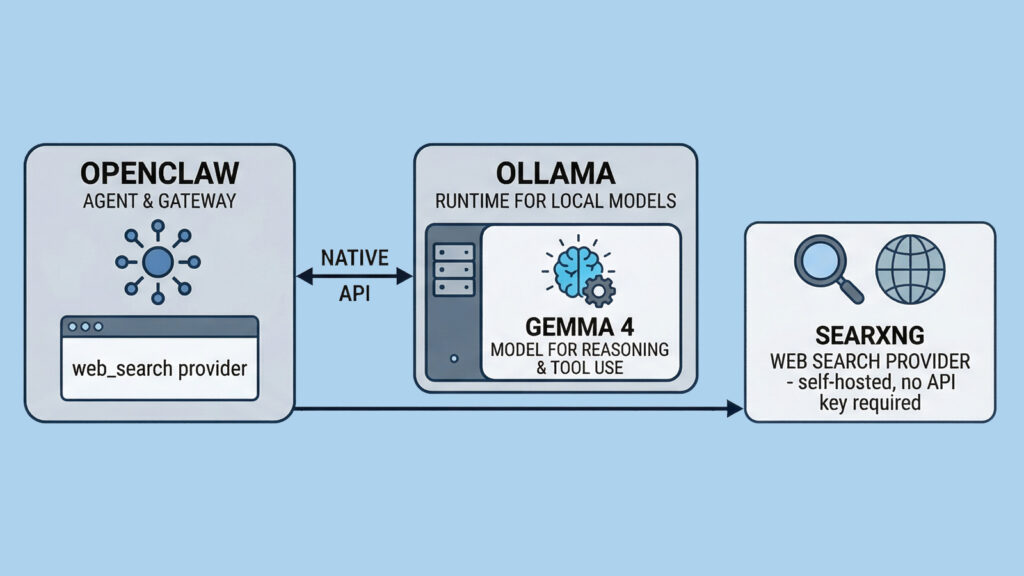
Vì sao nên chọn Gemma 4 cho OpenClaw?
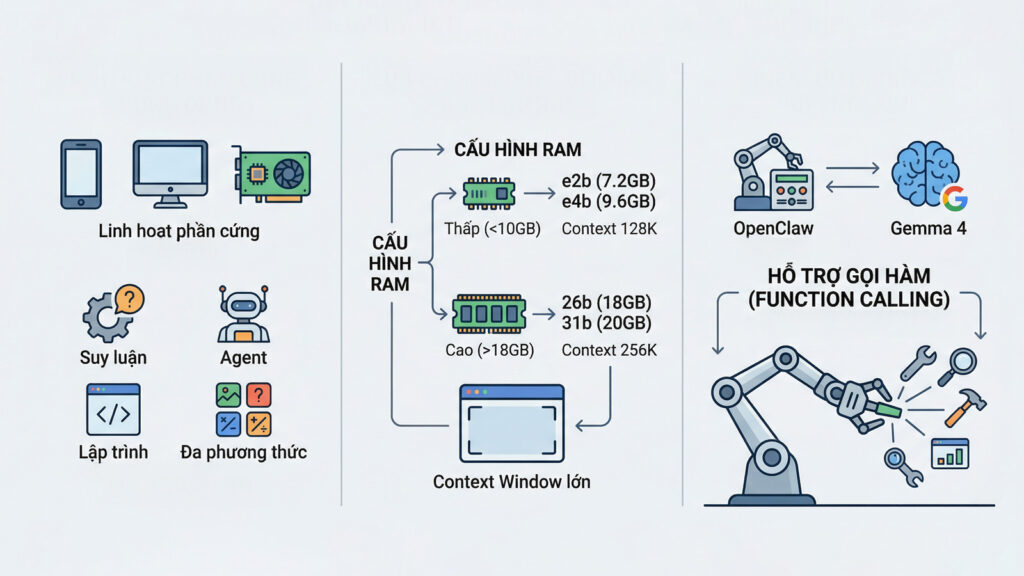
Gemma 4 là họ model của Google, được thiết kế cho nhiều mức phần cứng khác nhau, từ thiết bị edge/mobile đến workstation và GPU tiêu dùng. Google mô tả dòng model này là phù hợp cho reasoning, agentic workflows, coding và multimodal understanding; model card cũng nêu rõ các mức context window lên tới 128K cho E2B/E4B và 256K cho 26B A4B/31B.
Nếu xét theo cách triển khai thực tế với Ollama, các tag Gemma 4 phổ biến hiện nay gồm gemma4:e2b, gemma4:e4b, gemma4:26b và gemma4:31b. Ollama hiện công bố kích thước tham khảo lần lượt khoảng 7.2 GB, 9.6 GB, 18 GB và 20 GB, với context 128K hoặc 256K tùy bản. Vì vậy, nếu máy còn hạn chế RAM, nên bắt đầu từ e2b hoặc e4b; nếu phần cứng mạnh hơn, 26b hoặc 31b sẽ phù hợp hơn cho các workflow dài và nặng hơn.
Một điểm quan trọng khác là Gemma 4 có hỗ trợ function calling trong model card chính thức. Đây là yếu tố rất quan trọng với OpenClaw, vì agent không chỉ cần trả lời văn bản mà còn phải biết gọi tool đúng lúc để thực hiện chuỗi thao tác nhiều bước.
Chuẩn bị trước khi cài đặt
Để dựng cấu hình này, bạn nên chuẩn bị bốn thứ: OpenClaw đã cài và chạy được, Ollama để chạy model local, Docker để chạy SearXNG, và đủ dung lượng RAM/ổ đĩa cho model bạn chọn. OpenClaw docs hiện khuyến nghị thiết lập Ollama qua onboarding, còn SearXNG có thể chạy nhanh bằng container Docker.
Nếu muốn đi theo hướng đơn giản và dễ kiểm soát nhất, nên triển khai theo thứ tự sau: cài Ollama, tải Gemma 4, kết nối Ollama với OpenClaw, sau đó mới thêm SearXNG cho web search. Trình tự này cũng giúp bạn tách lỗi model khỏi lỗi web search trong quá trình test.
Bước 1: Cài Ollama
Trên Linux, lệnh cài nhanh chính thức của Ollama hiện là:
curl -fsSL https://ollama.com/install.sh | shNếu đang dùng macOS hoặc Windows, bạn có thể cài từ bộ cài chính thức của Ollama. Sau khi cài xong, hãy bảo đảm Ollama chạy được và sẵn sàng phục vụ model local.
Bước 2: Tải model Gemma 4
Sau khi có Ollama, bạn có thể tải model bằng lệnh ollama pull. Ví dụ:
ollama pull gemma4:e2b
ollama pull gemma4:e4bNếu máy mạnh hơn, bạn có thể dùng:
ollama pull gemma4:26b
ollama pull gemma4:31bĐể kiểm tra những model đã có trong máy, dùng:
ollama listCách làm này bám sát đúng luồng thiết lập: tải model vào máy trước, sau đó mới để OpenClaw nhận diện và dùng model đó.
Bước 3: Kết nối Ollama với OpenClaw
Cách được OpenClaw khuyến nghị hiện nay là chạy onboarding:
openclaw onboardTrong quá trình này, hãy chọn Ollama làm provider. OpenClaw sẽ hỏi base URL của Ollama, mặc định là http://127.0.0.1:11434, sau đó cho phép chọn chế độ Local hoặc Cloud + Local, phát hiện model sẵn có và gợi ý model mặc định.
Nếu bạn chỉ dùng local model, hãy chọn Local. Nếu muốn có thêm phương án dự phòng trên cloud cho máy yếu hoặc VPS không đủ tài nguyên, OpenClaw cũng hỗ trợ Cloud + Local. Trong docs hiện tại, các cloud model tiêu biểu được nhắc tới gồm kimi-k2.5:cloud, minimax-m2.7:cloud và glm-5.1:cloud.
LƯU Ý QUAN TRỌNG:
Khi nối OpenClaw với Ollama, cần dùng native API URL của Ollama, tức dạng
http://host:11434, không dùng endpoint OpenAI-compatible có đuôi/v1. OpenClaw docs cảnh báo rõ rằng dùng/v1có thể làm hỏng tool calling hoặc khiến model in raw tool JSON ra như văn bản thường.
Nếu cần quản lý gateway thủ công sau khi đổi cấu hình, OpenClaw có CLI cho service management, bao gồm cả lệnh restart:
openclaw gateway restartLệnh openclaw gateway restart hiện nằm trong nhóm lệnh quản lý Gateway chính thức.
Bước 4: Test model sau khi kết nối
Sau khi chọn model trong OpenClaw, nên thử bằng một câu ngắn trước thay vì ném ngay một tác vụ dài. Lần phản hồi đầu tiên thường chậm hơn vì model phải được nạp vào RAM; những lượt sau thường nhanh hơn khi phiên làm việc đã “ấm” lên. Đây là hành vi hoàn toàn bình thường khi chạy model local.
Sau bước test cơ bản, bạn có thể chuyển sang những tác vụ sát nhu cầu thực tế hơn như đọc file, chỉnh sửa nội dung, tổng hợp thông tin hoặc xử lý workflow nhiều bước. Đây là lúc mới đánh giá đúng model có hợp với máy và với kiểu công việc của bạn hay không.
Bước 5: Thêm web search tự host bằng SearXNG
Khi đã có model local, bước tiếp theo là bổ sung khả năng tìm kiếm web. OpenClaw hiện hỗ trợ SearXNG như một provider web_search tự host, không cần API key. Về bản chất, SearXNG là một metasearch engine: nó tổng hợp kết quả từ nhiều search services khác nhau thay vì phụ thuộc vào một nhà cung cấp duy nhất.
Việc tự chạy SearXNG không có nghĩa là internet “biến mất” khỏi bài toán tìm kiếm, nhưng nó giúp bạn tự kiểm soát instance, log và cấu hình riêng tư tốt hơn. Theo tài liệu chính thức của SearXNG, hệ thống này loại bỏ nhiều dữ liệu riêng tư khỏi request gửi tới search services, không chuyển quảng cáo hay tracking từ bên thứ ba, và có thể cấu hình thêm proxy hoặc Tor nếu cần.
Cách chạy nhanh nhất theo OpenClaw docs là:
docker run -d -p 8888:8080 searxng/searxngSau đó cấu hình OpenClaw dùng SearXNG bằng một trong hai cách:
openclaw configure --section webhoặc đặt biến môi trường:
export SEARXNG_BASE_URL="http://localhost:8888"Đây là đúng luồng cấu hình mà OpenClaw tài liệu hóa cho SearXNG.
Bước 6: Bật JSON cho SearXNG
Đây là bước rất dễ bị bỏ sót. Search API của SearXNG hỗ trợ format=json, nhưng tài liệu chính thức nói rõ rằng định dạng đầu ra phải được bật trong settings.yml, dưới mục search. Nếu gọi một format chưa được bật, API sẽ trả về 403 Forbidden.
Tài liệu SearXNG cho biết file cấu hình người dùng mặc định nằm ở:
/etc/searxng/settings.ymlTrong cấu hình tham chiếu của SearXNG, phần search.formats mặc định thường chỉ có html. Vì vậy, để OpenClaw đọc kết quả JSON ổn định hơn, bạn nên sửa thành:
search:
formats:
- html
- jsonThông tin về vị trí settings.yml và ví dụ mặc định có formats: - html đều có trong tài liệu quản trị chính thức của SearXNG.
Sau khi chỉnh xong, hãy lưu file và restart lại container SearXNG để tiến trình nạp cấu hình mới. Đây là bước thực tế cần thiết để thay đổi trong settings.yml có hiệu lực.
Bước 7: Kiểm tra web search
Bạn có thể test trực tiếp API của SearXNG trước, ví dụ:
curl 'http://localhost:8888/search?q=ai&format=json'Nếu lệnh này trả về JSON hợp lệ, nghĩa là phần search API đã ổn. Từ đó, bạn quay lại OpenClaw và thử các prompt như “tìm tin AI mới nhất hôm nay” hoặc “tóm tắt 5 tin công nghệ quan trọng nhất”. Nếu OpenClaw đã gọi được SearXNG, agent sẽ có thể tìm, đọc và tóm tắt kết quả web thay vì chỉ trả lời từ kiến thức nội bộ của model.
Gợi ý chọn model theo phần cứng
Nếu bạn chỉ muốn có một cấu hình gọn, dễ chạy và dễ test, hãy bắt đầu với gemma4:e2b hoặc gemma4:e4b. Hai bản này nhỏ hơn, context vẫn khá rộng và phù hợp cho việc kiểm tra tool calling, đọc file và các tác vụ agent cơ bản. Nếu hệ thống chạy mượt, lúc đó mới nâng lên 26b hoặc 31b để có dư địa tốt hơn cho workflow dài và prompt nặng.
Trong trường hợp máy không đủ RAM hoặc bạn đang chạy trên VPS nhỏ, phương án hợp lý là dùng chế độ Cloud + Local trong OpenClaw onboarding. Cách này cho phép giữ mô hình local cho các tác vụ nhẹ nhưng vẫn có cloud model để dự phòng khi cần sức mạnh cao hơn.
Khi ghép OpenClaw với Ollama, Gemma 4 và SearXNG, bạn có thể xây dựng một agent tự host tương đối hoàn chỉnh: model chạy local, tool calling hoạt động trong OpenClaw, còn web search được xử lý qua một search layer do chính bạn kiểm soát. Đây là hướng triển khai rất phù hợp nếu bạn muốn giảm phụ thuộc vào API thương mại, tiết kiệm chi phí và giữ quyền kiểm soát cao hơn đối với hạ tầng AI của mình.