NemoClaw: Vận hành AI agent an toàn hơn với NVIDIA OpenShell và managed inference
Tóm tắt nhanh
- NemoClaw là reference stack mã nguồn mở của NVIDIA để chạy OpenClaw an toàn hơn trong môi trường sandbox của NVIDIA OpenShell.
- Trọng tâm kỹ thuật của NemoClaw là cô lập agent bằng policy theo lớp: filesystem, network, process và inference.
- “Managed inference” trong NemoClaw nghĩa là agent bên trong sandbox không gọi trực tiếp nhà cung cấp mô hình; mọi yêu cầu được OpenShell chặn, định tuyến và quản lý ở phía host.
- Với cách tiếp cận này, khóa API không đi vào sandbox, lưu lượng egress được kiểm soát, và việc đổi model hoặc nhà cung cấp có thể thực hiện ở runtime mà không cần viết lại agent.
Vì sao bảo mật vẫn là rào cản lớn cho AI agent doanh nghiệp
AI agent doanh nghiệp không còn là chatbot đơn giản. Chúng có thể đọc file, gọi API, truy cập dịch vụ nội bộ, thực hiện workflow dài hạn và tương tác liên tục với hệ thống sản xuất. Chính vì vậy, vấn đề không chỉ là “agent trả lời có tốt không”, mà là agent có bị giới hạn đúng mức hay không. Tài liệu chính thức của NemoClaw nêu rất rõ thách thức này: các autonomous agents như OpenClaw có thể tạo request mạng tùy ý, truy cập filesystem host và gọi bất kỳ inference endpoint nào; nếu không có guardrail, rủi ro bảo mật, chi phí và tuân thủ sẽ tăng nhanh khi agent chạy không giám sát.
Điểm này càng đáng chú ý nếu nhìn từ phía OpenClaw. Dự án OpenClaw thừa nhận rằng tool mặc định có thể chạy trên host trong phiên chính, tức agent có thể có quyền truy cập rất rộng khi bạn chạy nó theo cách thông thường. OpenClaw cũng khuyến nghị xem DM đến từ bên ngoài là đầu vào không tin cậy. Nói cách khác, bản thân OpenClaw rất mạnh về năng lực trợ lý đa kênh, nhưng khi đưa vào môi trường doanh nghiệp, lớp an toàn vận hành cần được tăng cường đáng kể.
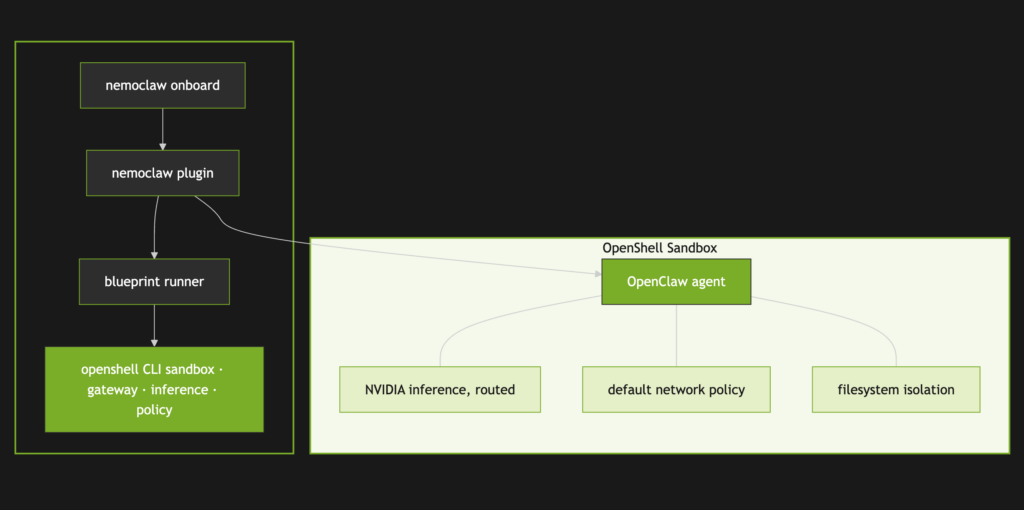
Kiến trúc NemoClaw trong NVIDIA OpenShell
NemoClaw không thay thế OpenClaw; nó đóng vai trò lớp hạ tầng bảo vệ và vận hành. Theo tài liệu của NVIDIA, NemoClaw là một reference stack mã nguồn mở giúp chạy OpenClaw “more safely” bằng cách cài NVIDIA OpenShell runtime, dùng các mô hình mở như NVIDIA Nemotron, rồi dựng một sandbox có chính sách bảo mật ngay từ lần khởi động đầu tiên. Về bản chất, OpenClaw là agent framework/trợ lý; OpenShell là runtime an toàn; còn NemoClaw là cầu nối và bộ orchestration để ráp hai lớp đó lại thành một stack có thể triển khai.
Cấu trúc host và sandbox
Kiến trúc chính thức của NemoClaw gồm hai phần: plugin TypeScript và blueprint Python. Plugin cung cấp CLI nemoclaw, đăng ký command và inference provider; blueprint là artifact được version hóa để tạo sandbox, áp policy, cấu hình inference route và gọi OpenShell CLI. Cách tách này rất quan trọng ở góc độ hạ tầng: plugin giữ mỏng và ổn định, còn logic triển khai thay đổi nhanh hơn được đẩy sang blueprint có kiểm tra version và digest. Đây là cách NVIDIA giảm rủi ro supply chain và tăng tính tái lập của quá trình setup.
Bên trong sandbox, OpenClaw chạy trong container được dựng sẵn, có NemoClaw plugin pre-installed, bị giới hạn egress theo policy, bị ràng buộc quyền filesystem và bị chặn không cho tự gọi trực tiếp inference provider. Ở phía host, OpenShell gateway giữ vai trò trung gian cho routing, policy enforcement và lưu credential. Đây là khác biệt mang tính nền tảng so với cách chạy agent “thẳng” trên máy chủ hay VM thông thường.
Bốn lớp kiểm soát bảo mật
OpenShell mô tả mô hình của mình là “defense in depth” trên bốn miền chính sách: filesystem, network, process và inference. NemoClaw kế thừa trực tiếp lớp bảo vệ đó. Ở mức filesystem, agent chỉ có read-write trên /sandbox và /tmp, còn phần lớn system path là read-only. Ở mức network, NemoClaw dùng deny-by-default: chỉ endpoint được khai báo mới được phép đi ra ngoài. Ở mức process, OpenShell chặn privilege escalation và syscall nguy hiểm. Ở mức inference, mọi cuộc gọi model bị reroute qua backend được kiểm soát.
Managed inference là gì và vì sao an toàn hơn
Khái niệm đáng giá nhất trong NemoClaw là managed inference. Theo tài liệu inference profiles, agent trong sandbox chỉ giao tiếp với inference.local. OpenShell đứng giữa, giữ credential ở host, rồi route lưu lượng đó đến provider mà bạn đã cấu hình trong quá trình onboarding, ví dụ NVIDIA Endpoints, OpenAI, Anthropic hay Google Gemini. Sandbox không bao giờ nhận raw API key.
Từ góc nhìn bảo mật, đây là cách làm an toàn hơn đáng kể so với việc nhét API key vào biến môi trường bên trong container agent. Thứ nhất, credential isolation tốt hơn vì khóa ở host thay vì trong sandbox. Thứ hai, egress được bó buộc: agent không thể lén gọi một model endpoint khác ngoài route đã khai báo. Thứ ba, provider và model được kiểm tra trong lúc onboard; nếu validation fail, quá trình tạo sandbox sẽ dừng lại. Thứ tư, khi cần đổi model, bạn chỉ thay OpenShell route mà không cần tái cấu trúc ứng dụng agent.
Về hiệu năng vận hành, managed inference còn giảm gánh nặng quản lý mô hình. Nếu dùng NVIDIA Endpoints, bạn tận dụng được mô hình cloud-hosted như Nemotron mà agent vẫn nhìn thấy một endpoint nội bộ thống nhất. Nếu muốn thay đổi model cho workload khác, bạn có thể đổi route tại runtime bằng openshell inference set mà không cần restart sandbox. Điều này giúp tối ưu độ trễ theo use case và giảm công việc bảo trì khi cần chuyển đổi giữa model nhẹ, model reasoning mạnh hoặc backend khác nhau.
Hướng dẫn chuẩn bị môi trường NVIDIA
Tại thời điểm tài liệu hiện tại, NVIDIA ghi rõ NemoClaw đang ở trạng thái alpha và chưa nên dùng trực tiếp cho production. Với đội hạ tầng, điều này có nghĩa là phù hợp nhất cho lab, pilot hoặc môi trường kiểm thử tăng cường bảo mật trước khi mở rộng sang hệ thống chính thức.
Yêu cầu phần cứng và phần mềm
Quickstart chính thức khuyến nghị tối thiểu 4 vCPU, 8 GB RAM, 20 GB đĩa trống; mức đề xuất là 16 GB RAM và 40 GB đĩa. Hệ điều hành ưu tiên là Ubuntu 22.04 LTS trở lên, cùng Node.js 20+, npm 10+, container runtime đang chạy và OpenShell đã được cài. NVIDIA cũng lưu ý image sandbox khoảng 2.4 GB nén; trên máy ít RAM, bạn có thể cần swap để tránh OOM trong lúc build/push image.
Với DGX Spark hoặc môi trường Ubuntu 24.04 dùng cgroup v2, NemoClaw có lệnh sudo nemoclaw setup-spark để áp các fix liên quan Docker và cgroup trước khi onboard. Nếu doanh nghiệp có hạ tầng GPU từ NVIDIA, đây là bước nên đưa vào checklist chuẩn hóa máy chủ.
Các bước cài đặt chi tiết qua CLI
Luồng cài đặt chính thức được NVIDIA tối giản khá tốt. Cách nhanh nhất là chạy script cài đặt:
curl -fsSL https://www.nvidia.com/nemoclaw.sh | bashScript này sẽ cài Node.js nếu cần, sau đó chạy guided onboarding để tạo OpenShell gateway, đăng ký inference provider, build sandbox image và áp security policy. Sau khi hoàn tất, bạn nhận được tên sandbox, model đang dùng và các lệnh thao tác tiếp theo.
Nó sẽ tương tự như này:
──────────────────────────────────────────────────
Sandbox my-assistant (Landlock + seccomp + netns)
Model nvidia/nemotron-3-super-120b-a12b (NVIDIA Endpoints)
──────────────────────────────────────────────────
Run: nemoclaw my-assistant connect
Status: nemoclaw my-assistant status
Logs: nemoclaw my-assistant logs --follow
──────────────────────────────────────────────────
[INFO] === Installation complete ===Sau khi cài xong, quy trình vận hành ban đầu sẽ như này:
nemoclaw onboard
nemoclaw my-assistant connect
openclaw tuiNếu cần gửi một lệnh nhanh thay vì vào TUI, trong sandbox shell bạn có thể dùng:
openclaw agent --agent main --local -m "hello" --session-id testCác lệnh quản trị quan trọng khác gồm nemoclaw my-assistant status, nemoclaw my-assistant logs --follow, nemoclaw list và nemoclaw my-assistant destroy. Đây là bộ CLI đủ để đội hạ tầng theo dõi vòng đời sandbox từ setup đến debug.
Cấu hình managed inference để tối ưu tài nguyên GPU
Nếu mục tiêu là giảm tải quản trị model, hướng đi tự nhiên là dùng routed inference với NVIDIA Endpoints hoặc provider cloud khác. Khi đó, GPU nội bộ không phải gánh inference mặc định, nhưng agent vẫn ở trong sandbox và vẫn giữ được credential isolation. Còn nếu muốn tối ưu theo hướng riêng tư nội bộ hoặc chạy always-on trên GPU từ xa, NemoClaw hỗ trợ deploy lên remote GPU instance qua nemoclaw deploy, đồng thời cho phép chọn cấu hình GPU bằng biến NEMOCLAW_GPU.
OpenShell cũng hỗ trợ truyền host GPU vào sandbox cho local inference hoặc GPU workload. Điều này mở ra mô hình kết hợp: dev/test có thể dùng managed cloud inference để giảm vận hành; các workload nhạy cảm hoặc yêu cầu latency thấp có thể chuyển sang local GPU path khi hạ tầng đã sẵn sàng. Thêm một lợi thế vận hành là runtime switching: bạn đổi provider hoặc model bằng openshell inference set mà sandbox vẫn tiếp tục dùng inference.local, giúp abstraction ở tầng agent không thay đổi.
Cách vận hành OpenClaw an toàn bên trong sandbox
NemoClaw dùng deny-by-default network policy. Khi agent gọi một host chưa nằm trong policy, OpenShell chặn kết nối và hiển thị yêu cầu trong TUI để operator phê duyệt hoặc từ chối. Đây là cơ chế rất phù hợp cho môi trường doanh nghiệp vì vừa giữ an toàn mặc định, vừa không cứng nhắc tuyệt đối. Bạn có thể quan sát các request bị chặn, active network connections và trạng thái inference routing bằng lệnh openshell term.
Từ góc nhìn riêng tư, lợi ích lớn nhất là agent không tự do thoát ra Internet, không cầm trực tiếp khóa provider và không có quyền ghi tùy ý lên host filesystem. Từ góc nhìn độ trễ, lợi ích nằm ở việc inference route được chuẩn hóa, có thể đổi nhanh theo backend tối ưu hơn mà không cần sửa agent logic. Với các agent workflow luôn bật, đây là cách tiếp cận thực tế hơn rất nhiều so với mô hình chạy agent có toàn quyền trên host.
NemoClaw là nỗ lực đáng chú ý của NVIDIA nhằm biến OpenClaw từ một agent mạnh về tính năng thành một tác nhân có thể vận hành an toàn hơn trong môi trường kiểm soát. Giá trị thực sự của nó không nằm ở một model mới, mà ở cách kết hợp OpenClaw, OpenShell và inference routing thành một kiến trúc có sandbox, policy, operator approval và managed inference ngay từ đầu. Với kỹ sư hệ thống và đội AI platform, đây là hướng triển khai rất đáng nghiên cứu nếu mục tiêu là agentic workflow trên hạ tầng NVIDIA nhưng vẫn giữ kiểm soát bảo mật, quyền riêng tư và chi phí vận hành.