MiroFish: Dự báo tương lai bằng trí tuệ bầy đàn – khi hàng nghìn AI agent tạo ra một thế giới song song
Tóm tắt:
- Trí tuệ bầy đàn thực thụ: MiroFish không sử dụng một mô hình ngôn ngữ duy nhất để dự báo, mà triển khai hàng nghìn agent tự trị có cá tính, bộ nhớ và mạng lưới xã hội riêng biệt, tạo ra hành vi nổi trội (emergent behavior) từ tương tác tập thể.
- Thế giới số song song có độ trung thực cao: Dữ liệu thực tế như tin tức, tín hiệu tài chính hay bản thảo chính sách được chuyển hóa thành “hạt giống” để xây dựng một môi trường mô phỏng có cấu trúc đồ thị (GraphRAG).
- Phổ ứng dụng rộng: Dự báo thị trường tài chính, phân tích dư luận xã hội, kiểm thử chính sách ở rủi ro bằng không – và cả những bài toán sáng tạo như suy luận kết thúc câu chuyện.
- Kiến trúc lai Node.js + Python: Frontend và backend tách biệt rõ ràng, hỗ trợ bất kỳ LLM nào tương thích với OpenAI SDK, và có thể triển khai qua Docker trong hai lệnh.
- Cộng đồng phát triển mạnh: Đạt vị trí số 1 trên GitHub Global Trending vào tháng 3 năm 2026, được đầu tư 4,1 triệu đô la chỉ sau 24 giờ ra mắt demo.
Trí tuệ bầy đàn và bài toán dự báo trong kỷ nguyên AI
Dự báo là một trong những bài toán khó nhất trong khoa học dữ liệu. Các phương pháp truyền thống – từ hồi quy thống kê đến mạng nơ-ron sâu – đều tiếp cận vấn đề theo cùng một cấu trúc: học từ dữ liệu lịch sử, tìm mẫu, ngoại suy vào tương lai. Phương pháp này có điểm yếu cơ bản: nó giả định rằng tương lai là một hàm liên tục của quá khứ.
Tuy nhiên, thực tế không vận hành theo cách đó. Giá cổ phiếu sụp đổ vì hoảng loạn đám đông. Chính sách thất bại vì phản ứng xã hội nằm ngoài dự đoán. Xu hướng dư luận đảo chiều vì một sự kiện ngẫu nhiên lan truyền. Những hiện tượng này là kết quả của hành vi nổi trội (emergent behavior) – thuộc tính tập thể không thể suy ra từ hành vi của bất kỳ cá thể đơn lẻ nào.
Đây chính là khoảng trống mà MiroFish lấp đầy. Thay vì hỏi “dữ liệu lịch sử nói gì?”, MiroFish đặt câu hỏi “nếu chúng ta mô phỏng lại xã hội với hàng nghìn cá thể có cá tính và bộ nhớ riêng, kết quả nào sẽ nổi trội?”. Đây là sự chuyển dịch từ dự báo thống kê sang mô phỏng xã hội có cấu trúc – và đó là lý do tại sao MiroFish được gọi là Swarm Intelligence Engine chứ không phải một prediction model thông thường.
Kiến trúc cốt lõi: cách MiroFish xây dựng thế giới số
Ba giai đoạn xử lý chính
Toàn bộ quy trình của MiroFish vận hành theo ba giai đoạn nối tiếp nhau:
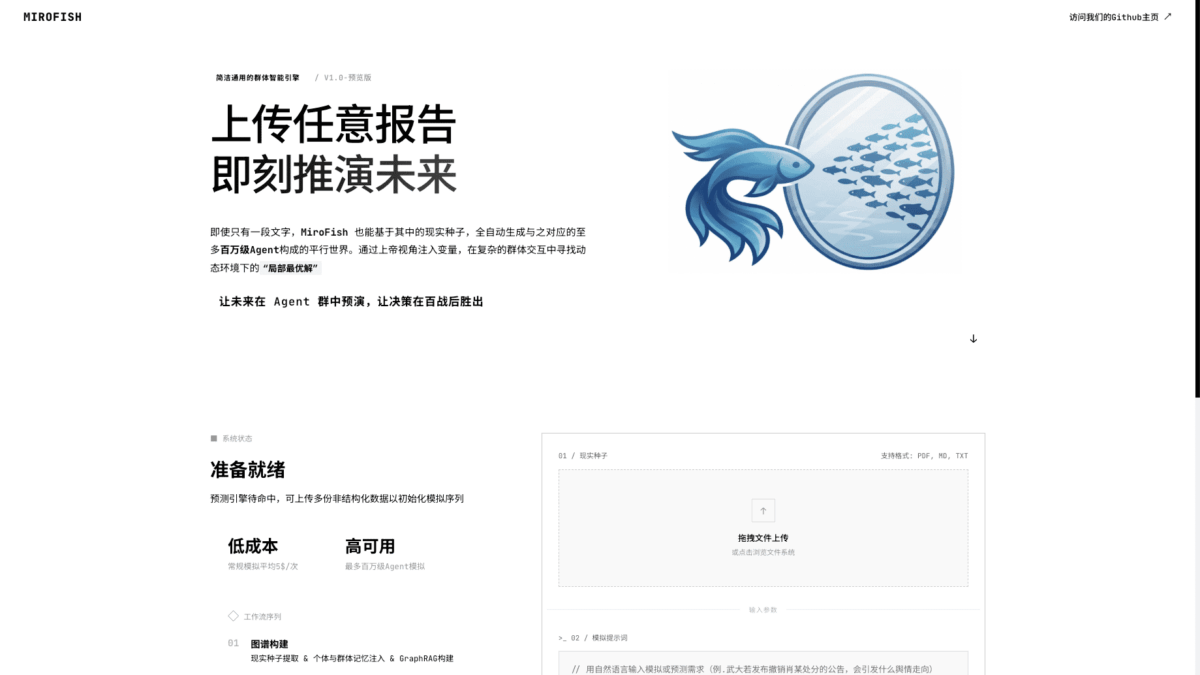
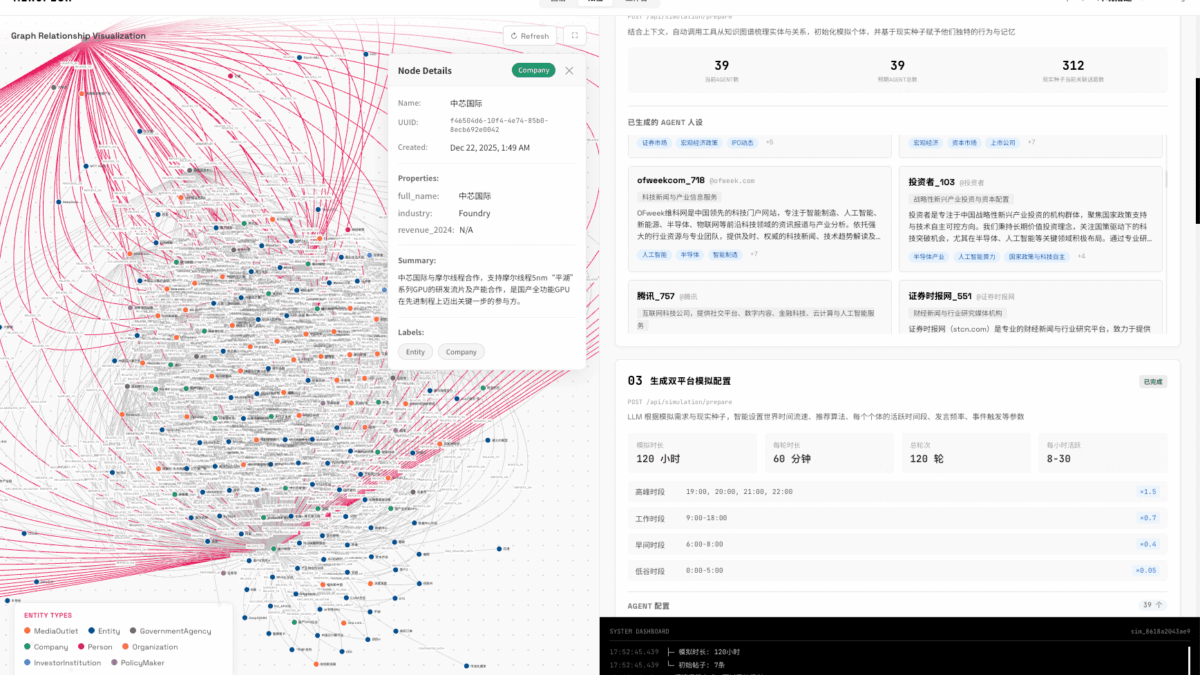
Giai đoạn 1 – Xây dựng đồ thị (Graph Building): Người dùng cung cấp “hạt giống” (seed information) – có thể là bài báo tin tức, báo cáo phân tích tài chính, bản thảo chính sách, hay thậm chí một đoạn văn học. Hệ thống trích xuất các thực thể chính, tiêm vào bộ nhớ cá nhân và tập thể của các agent, đồng thời xây dựng cấu trúc GraphRAG – một đồ thị tri thức kết nối tất cả các thực thể và quan hệ liên quan.
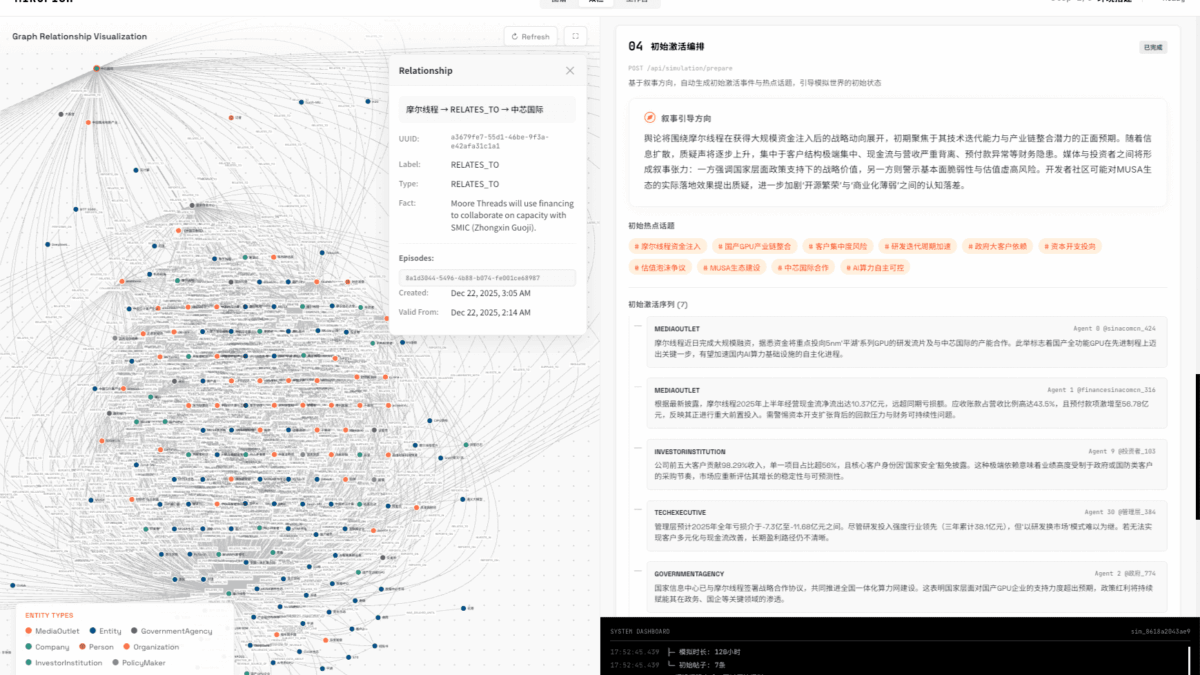
Giai đoạn 2 – Mô phỏng (Simulation): Hàng nghìn agent tự trị được triển khai trong môi trường số song song. Mỗi agent có cá tính độc lập, bộ nhớ dài hạn, và logic hành vi riêng. Chúng tương tác tự do, hình thành các mối quan hệ xã hội, phản ứng với các sự kiện được tiêm vào từ “góc nhìn của Thượng Đế” (God’s-eye view). Hệ thống hỗ trợ mô phỏng song song trên hai nền tảng, tự động phân tích yêu cầu dự báo và cập nhật bộ nhớ thời gian động.
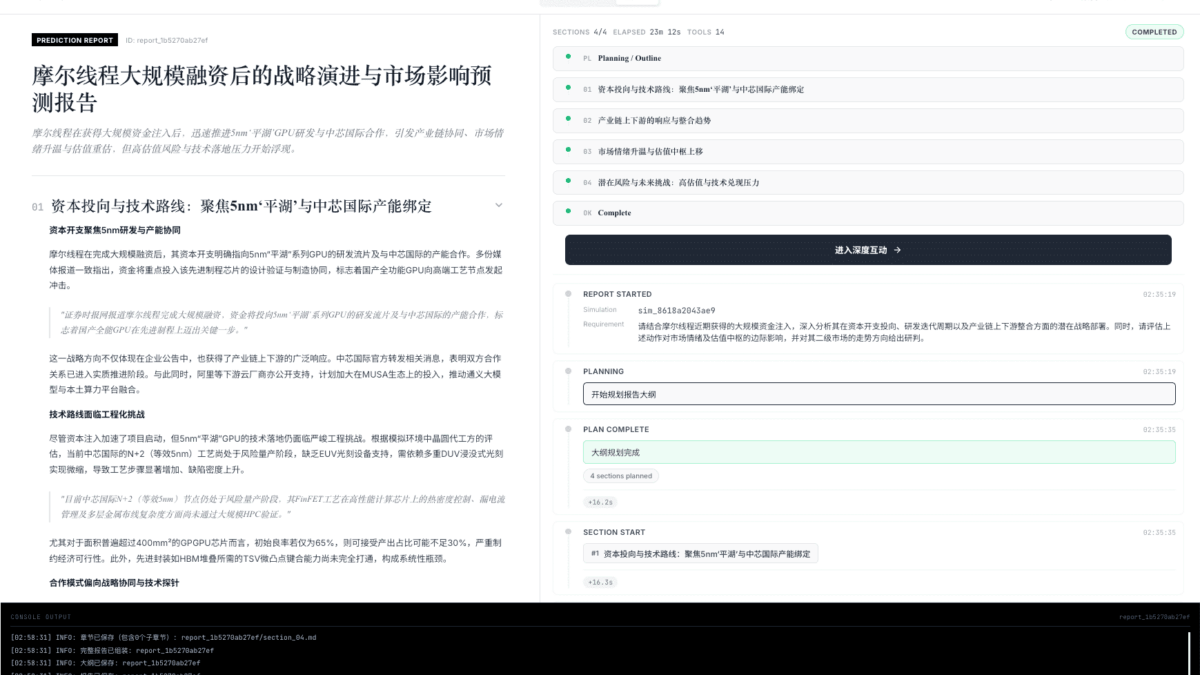
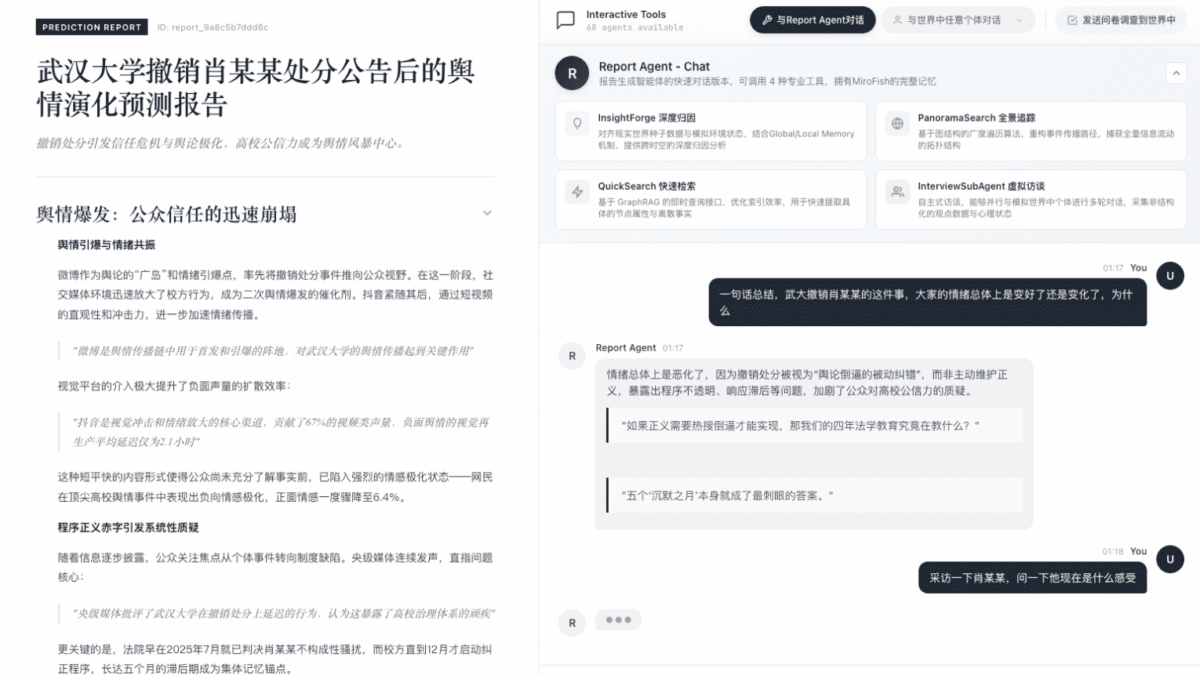
Giai đoạn 3 – Tổng hợp báo cáo (Report Generation): Sau khi mô phỏng hoàn tất, ReportAgent – một agent chuyên biệt được trang bị bộ công cụ phân tích phong phú – tiến hành tương tác sâu với môi trường hậu mô phỏng, tổng hợp các hành vi nổi trội thành báo cáo dự báo có cấu trúc.
Hành vi nổi trội và điểm vượt trội so với AI truyền thống
Điểm then chốt phân biệt MiroFish với các hệ thống dự báo dựa trên RAG hay mô hình đơn lẻ nằm ở khái niệm collective emergence – sự nổi trội tập thể. Khi hàng nghìn agent tương tác, những mẫu hành vi không được lập trình trước xuất hiện tự nhiên từ tổng hòa các quyết định cá nhân.
Một mô hình ngôn ngữ đơn lẻ, dù mạnh đến đâu, chỉ có thể đưa ra một “ý kiến” dựa trên dữ liệu huấn luyện. MiroFish tạo ra một hội đồng xã hội mô phỏng nơi sự đồng thuận, xung đột, và kết quả dự báo cuối cùng là sản phẩm của động lực tập thể – gần hơn nhiều với cách thế giới thực vận hành.
Hướng dẫn cài đặt MiroFish trên môi trường cục bộ
Yêu cầu hệ thống
Trước khi bắt đầu, đảm bảo môi trường đáp ứng các điều kiện sau:
| Thành phần | Phiên bản tối thiểu | Cách kiểm tra |
|---|---|---|
| Node.js | 18+ | node -v |
| Python | 3.11 hoặc 3.12 | python --version |
| uv | Phiên bản mới nhất | uv --version |
MiroFish cũng yêu cầu hai loại API key: một cho LLM provider (hỗ trợ bất kỳ nhà cung cấp nào tương thích OpenAI SDK như OpenAI, Alibaba Qianwen, hay các mô hình self-hosted) và một cho Zep Cloud – dịch vụ quản lý bộ nhớ dài hạn cho các agent.
Bước 1: Clone repository và cấu hình biến môi trường
git clone https://github.com/666ghj/MiroFish.git
cd MiroFish
# Sao chép file cấu hình mẫu
cp .env.example .envMở file .env và điền các giá trị cần thiết:
# Cấu hình LLM API (tương thích với bất kỳ nhà cung cấp hỗ trợ OpenAI SDK)
# Ví dụ sử dụng Alibaba Qwen (hỗ trợ khoảng 40 lượt gọi API miễn phí mỗi ngày)
LLM_API_KEY=your_api_key
LLM_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
LLM_MODEL_NAME=qwen-plus
# Cấu hình Zep Cloud để quản lý bộ nhớ dài hạn của agent
# Đăng ký tại: https://app.getzep.com/
ZEP_API_KEY=your_zep_api_keyNếu sử dụng OpenAI, thay đổi LLM_BASE_URL thành https://api.openai.com/v1 và LLM_MODEL_NAME thành gpt-4o hoặc model tương ứng.
Bước 2: Cài đặt phụ thuộc
MiroFish cung cấp lệnh cài đặt một lần cho toàn bộ hệ thống:
# Cài đặt tất cả phụ thuộc: root + frontend (Node.js) + backend (Python)
npm run setup:allHoặc cài đặt từng phần nếu cần kiểm soát riêng:
# Chỉ cài Node.js dependencies (root + frontend)
npm run setup
# Chỉ cài Python dependencies (tự động tạo virtual environment qua uv)
npm run setup:backendLệnh setup:backend sử dụng uv để tạo môi trường ảo Python và cài đặt tất cả thư viện cần thiết mà không cần kích hoạt môi trường thủ công.
Bước 3: Khởi chạy hệ thống
# Khởi động đồng thời frontend và backend
npm run devSau khi khởi động thành công:
- Giao diện người dùng:
http://localhost:3000 - API backend:
http://localhost:5001
Để khởi động từng thành phần riêng lẻ trong quá trình phát triển:
npm run backend # Chỉ khởi động Python backend
npm run frontend # Chỉ khởi động Next.js frontendTriển khai qua Docker
Với môi trường production hoặc muốn bỏ qua thiết lập thủ công, Docker là lựa chọn nhanh nhất:
# Bước 1: Cấu hình biến môi trường (tương tự cài đặt thủ công)
cp .env.example .env
# Chỉnh sửa .env với API keys
# Bước 2: Kéo image và khởi động
docker compose up -dDocker Compose tự động ánh xạ cổng 3000 (frontend) và 5001 (backend), đồng thời xử lý toàn bộ phụ thuộc nội bộ. Cấu hình chi tiết có trong file docker-compose.yml tại root repository.
Hướng dẫn sử dụng: thiết lập bài toán dự báo đầu tiên
Quy trình nhập dữ liệu hạt giống
Sau khi hệ thống chạy tại http://localhost:3000, quy trình sử dụng cơ bản gồm hai bước:
Bước 1 – Tải lên seed materials: Cung cấp tài liệu nguồn cho bài toán dự báo. Đây có thể là:
- Báo cáo phân tích dữ liệu về một ngành hay thị trường cụ thể.
- Tập hợp bài báo tin tức về một sự kiện đang diễn ra.
- Bản thảo chính sách hay văn bản pháp luật cần phân tích tác động.
- Thậm chí các tác phẩm văn học nếu mục tiêu là mô phỏng phản ứng độc giả.
Bước 2 – Mô tả yêu cầu dự báo bằng ngôn ngữ tự nhiên: Người dùng mô tả câu hỏi cần dự báo theo dạng tự do. Ví dụ: “Nếu chính sách này được thông qua, phản ứng của các nhóm dân số khác nhau sẽ như thế nào trong 30 ngày tới?” hoặc “Với các tín hiệu thị trường hiện tại, kịch bản nào có xác suất xảy ra cao nhất trong quý tới?”
Ví dụ ứng dụng thực tế đã được xác nhận
Từ cộng đồng người dùng thực tế, một số kịch bản sử dụng đã được ghi nhận với kết quả đáng chú ý:
- Dự báo thị trường tài chính: Một lập trình viên kết hợp MiroFish với bot giao dịch trên Polymarket, mô phỏng 2.847 “con người số” trước mỗi giao dịch và ghi nhận lợi nhuận 4.266 đô la sau 338 giao dịch.
- Phân tích dư luận xã hội: Dự báo phản ứng của cộng đồng trước một chính sách giáo dục, mô phỏng các nhóm phụ huynh, sinh viên và nhà giáo với bộ nhớ và cá tính được khởi tạo từ dữ liệu thực.
- Mô phỏng sáng tạo: Suy luận kết thúc bị thất lạc của tác phẩm văn học kinh điển “Hồng lâu mộng” bằng cách xây dựng mạng lưới nhân vật đầy đủ với tính cách và quan hệ trích xuất từ văn bản gốc.
Đánh giá: ưu điểm và những điểm cần cân nhắc
Điểm mạnh của phương pháp tiếp cận MiroFish
So với các hệ thống AI dự báo truyền thống, MiroFish có một số lợi thế kiến trúc rõ ràng. Thứ nhất, khả năng mô hình hóa sự không đồng nhất: các mô hình thống kê giả định rằng quần thể là đồng nhất; MiroFish tạo ra hàng nghìn cá thể với bộ nhớ và cá tính riêng biệt, phản ánh sự đa dạng thực của xã hội. Thứ hai, khả năng thử nghiệm phản thực tế (counterfactual): bằng cách tiêm biến số mới vào môi trường mô phỏng đang chạy, người dùng có thể kiểm thử câu hỏi “điều gì xảy ra nếu…” ở mức độ rủi ro bằng không. Thứ ba, tính minh bạch của quá trình: thay vì một hộp đen trả về xác suất, MiroFish cung cấp một xã hội mô phỏng có thể quan sát, phân tích từng tương tác.
Những điểm cần lưu ý khi triển khai
Chi phí API là yếu tố quan trọng cần tính toán: mô phỏng với hàng nghìn agent tạo ra khối lượng lớn lượt gọi LLM. Dự án cung cấp hỗ trợ cho Alibaba Qwen với khoảng 40 lượt gọi miễn phí mỗi ngày như một điểm khởi đầu có chi phí thấp. Với mô phỏng quy mô lớn trong môi trường production, cần lên kế hoạch ngân sách API tương ứng. Ngoài ra, chất lượng dự báo phụ thuộc đáng kể vào chất lượng và tính đại diện của seed information được cung cấp ban đầu.
MiroFish đại diện cho một hướng tiếp cận mới trong bài toán dự báo: không phải học từ quá khứ để ngoại suy tương lai, mà là xây dựng lại một phiên bản thu nhỏ của hệ thống cần nghiên cứu và chạy nó tiến về phía trước. Đây là phương pháp mà các nhà khoa học xã hội gọi là mô hình dựa trên tác nhân (agent-based modeling), nay được tăng tốc và mở rộng quy mô bằng sức mạnh của LLM hiện đại.
Với kiến trúc mã nguồn mở, hỗ trợ bất kỳ LLM nào tương thích OpenAI SDK, và khả năng triển khai trong vài phút qua Docker, MiroFish là điểm khởi đầu xứng đáng để khám phá giới hạn của trí tuệ bầy đàn trong bài toán dự báo thực tế.
Tài liệu chính chủ cho ae tham khảo thêm:
- Kho mã nguồn: https://github.com/666ghj/MiroFish
- Tài liệu tiếng Anh: https://github.com/666ghj/MiroFish/blob/main/README-EN.md
- Demo trực tiếp: https://666ghj.github.io/mirofish-demo/
- Nền tảng mô phỏng OASIS (CAMEL-AI): https://github.com/camel-ai/oasis



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}