Hướng dẫn xây dựng RAG Agent “không Vector DB” với Gemini File Search API trên n8n
Nếu bạn đã từng “đổ mồ hôi” xây dựng hệ thống RAG (Retrieval-Augmented Generation) với các bước phức tạp: chunking văn bản, tạo embedding, và quản lý vector database (Pinecone, Supabase…), thì workflow n8n này chính là “liều thuốc giải” cho bạn.
Với Gemini File Search API, Google đã trừu tượng hóa toàn bộ quá trình lưu trữ và tìm kiếm vector. Chúng ta chỉ cần ném file vào, và Google lo phần còn lại. Bài viết này sẽ phân tích chi tiết workflow n8n đính kèm, giúp bạn xây dựng một RAG Agent mạnh mẽ, rẻ tiền (gần như miễn phí lưu trữ) và đặc biệt là có sẵn quy trình tự động đánh giá chất lượng câu trả lời.
Tổng quan workflow n8n
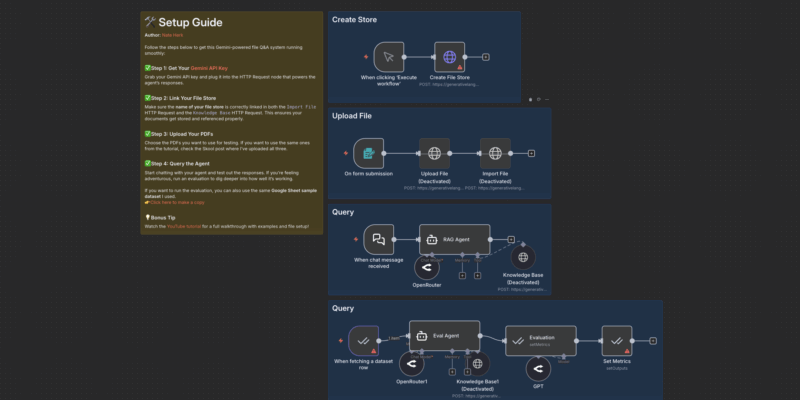
Downlaod workflow: https://romhub.io/n8n/Gemini_File_SearchDựa trên file JSON cấu hình, workflow của chúng ta được chia thành 3 phân hệ chính hoạt động độc lập nhưng bổ trợ cho nhau:
- Hệ thống Ingestion (Nạp dữ liệu): Tạo kho lưu trữ và đẩy file PDF vào đó.
- Hệ thống Chat (RAG Agent): AI Agent trả lời câu hỏi dựa trên dữ liệu đã nạp.
- Hệ thống Evaluation (Đánh giá): Tự động chấm điểm độ chính xác của AI dựa trên tập dữ liệu mẫu từ Google Sheets.
Hãy đi sâu vào từng bước kỹ thuật.
Phần 1: Thiết lập kho chứa & nạp dữ liệu (Setup & Ingestion)
Trong workflow này, việc xử lý dữ liệu không cần code, chỉ dùng các node HTTP Request tiêu chuẩn để gọi API của Google.
Bước 1: Khởi tạo “File Store” (Manual Trigger)
Trước khi upload bất cứ thứ gì, chúng ta cần một cái “kho”. Trong workflow, nhánh này bắt đầu bằng node When clicking ‘Execute workflow’.
- Node:
Create File Store(HTTP Request). - Hành động: Gửi lệnh
POSTđếnfiles.stores.create. - Body: Đặt
displayNamecho kho của bạn (ví dụ: “Tai-lieu-Du-an-A”).
LƯU Ý:
Sau khi chạy node này một lần duy nhất, Google sẽ trả về một ID (dạng corpora/xxx hoặc fileStores/xxx). Bạn cần copy ID này để cấu hình cho các node tiếp theo.Bước 2: Upload & import file (Form Trigger)
Đây là quy trình nạp tài liệu tự động. Bạn upload file qua Form, n8n sẽ xử lý:
- Node:
Upload File.- Sử dụng endpoint
/upload/v1beta/files. - Quan trọng: Node này gửi dữ liệu dưới dạng
Binary File. Lúc này file mới chỉ nằm trên Cloud của Google (dạng file mồ côi), chưa thuộc về kho nào cả.
- Sử dụng endpoint
- Node:
Import File.- Đây là bước “gắp” file vừa upload bỏ vào kho đã tạo ở Bước 1.
- Sử dụng endpoint
:importFile. - Lúc này, Google sẽ tự động xử lý embedding và indexing cho file đó. Bạn không cần làm gì thêm.
Phần 2: Xây dựng “bộ não” RAG Agent
Đây là nơi điều kỳ diệu xảy ra. Thay vì phải tự code logic tìm kiếm, chúng ta dùng khả năng Tool calling của Gemini.
Cấu hình Agent
- Trigger:
When chat message received. - Model: Sử dụng
OpenRouterhoặc node Google Gemini trực tiếp (trong file JSON đang dùng OpenRouter để gọi model GPT-5-mini làm nền tảng, nhưng sức mạnh nằm ở Tool). - Tool:
Knowledge Base(HTTP Request Tool).
Sức mạnh của Node “Knowledge Base Tool”
Đây không phải là một node tìm kiếm bình thường. Nó được cấu hình như một công cụ để Agent sử dụng khi cần thiết.
- Cơ chế: Khi người dùng hỏi một câu cần dữ liệu (ví dụ: “Doanh thu Apple năm 2024 là bao nhiêu?”), Agent sẽ kích hoạt tool này.
- API Call: Tool này gọi trực tiếp đến
models/gemini-2.5-flash:generateContent. - Payload đặc biệt: Điểm mấu chốt nằm ở phần
toolstrong body request:
"tools": [
{
"file_search": {
"file_search_store_names": [
"YOUR FILE STORE" // Điền ID kho của bạn vào đây
]
}
}
]Dòng code trên ra lệnh cho model Gemini 2.5 Flash: “Hãy dùng tính năng File Search, tìm trong kho dữ liệu này, và trả lời câu hỏi”. Mô hình sẽ tự động trích xuất thông tin (retrieval) và tạo câu trả lời (generation) trong một lần gọi API duy nhất.
Phần 3: Hệ thống tự động đánh giá (Automated Evaluation)
Điểm sáng nhất của workflow này là quy trình kiểm thử chất lượng (Quality Assurance) tự động, giúp bạn tránh tình trạng “Rác vào – Rác ra”.
Quy trình hoạt động:
- Nguồn dữ liệu test: Node
When fetching a dataset rowsẽ lấy từng dòng từ một Google Sheet (chứa Cột: Câu hỏi và Câu trả lời mong đợi). - RAG Agent trả lời: Node
Eval Agentsẽ chạy câu hỏi đó qua hệ thống Gemini File Search để lấy câu trả lời thực tế. - LLM Chấm điểm: Node
Evaluation(sử dụng một LLM khác) đóng vai trò là giám khảo. Nó sẽ so sánh Câu trả lời của Agent với Câu trả lời mong đợi (Ground Truth). - Ghi lại kết quả: Điểm số (thang 1-5) và lý do chấm điểm sẽ được ghi ngược lại vào Google Sheet qua node
Set Metrics.
Tại sao điều này quan trọng?
Khi bạn thay đổi prompt hệ thống hoặc cấu hình model, làm sao bạn biết Agent có thông minh hơn không hay đang ngu đi? Hệ thống evaluation này cung cấp con số định lượng chính xác (ví dụ: độ chính xác tăng từ 3.5 lên 4.2), giúp bạn tối ưu hóa Agent một cách khoa học thay vì cảm tính.
Những lưu ý “sống còn” khi triển khai
Dựa trên kinh nghiệm chạy workflow này, đây là những điểm bạn cần chú ý:
- Thay thế “YOUR FILE STORE”: Trong file JSON, các vị trí
YOUR FILE STOREcần được thay thế thủ công bằng ID thực tế bạn nhận được ở Bước 1. Nếu quên bước này, Agent sẽ không tìm thấy dữ liệu. - Chi phí: Dù lưu trữ miễn phí, nhưng mỗi lần chạy node Evaluation (Đánh giá), bạn sẽ tốn token cho cả Agent trả lời và LLM chấm điểm. Hãy cân nhắc số lượng row trong Google Sheet khi chạy test.
- Model Selection: Workflow đang sử dụng
gemini-2.5-flashcho việc truy xuất dữ liệu. Đây là lựa chọn tối ưu nhất hiện nay về tốc độ/giá cả (Rẻ hơn GPT-4o rất nhiều nhưng khả năng xử lý context dài cực tốt). - Dữ liệu trùng lặp: Google File Search API hiện chưa tự động lọc file trùng. Nếu bạn chạy nút Import 2 lần cho cùng 1 file, nó sẽ lưu 2 bản copy, làm loãng kết quả tìm kiếm. Hãy xóa file cũ trong Store trước khi update file mới.
Workflow n8n này không chỉ đơn thuần là một tính năng “Chat với PDF”. Nó là một quy trình DevOps thu nhỏ cho AI: từ khâu Setup (Tạo store), Deploy (Upload file), Run (Chat Agent) đến Test (Evaluation).
Đây là giải pháp “ngon – bổ – rẻ” nhất hiện tại để triển khai RAG cho các doanh nghiệp vừa và nhỏ mà không muốn gánh chi phí hạ tầng Vector Database đắt đỏ.