Hướng dẫn tích hợp Qwen-Image vào Dify để xây dựng ứng dụng chỉnh sửa ảnh AI
Qwen-Image là một mô hình chuyển đổi văn bản thành hình ảnh mã nguồn mở đã thu hút sự chú ý rộng rãi nhờ khả năng xuất sắc trong việc hiển thị văn bản phức tạp, đặc biệt là tạo ký tự tiếng Trung. So với các mô hình phổ biến khác, Qwen-Image có thể nhúng chính xác nội dung văn bản nhiều dòng và nhiều đoạn vào hình ảnh, mở ra những khả năng mới cho thiết kế poster, sáng tạo nội dung và nhiều kịch bản ứng dụng khác.
Tuy nhiên, mặc dù bản thân các mô hình này là mã nguồn mở, chi phí để gọi các dịch vụ này thông qua các nền tảng thương mại thường khá cao. Ví dụ, các dịch vụ plugin do một số nền tảng cung cấp có thể tốn tới 0.25 đô la cho mỗi hình ảnh được tạo sau khi hết hạn mức miễn phí, đây là một khoản chi phí đáng kể đối với người dùng cần tạo số lượng lớn hoặc lặp lại thường xuyên.
Trong bài viết này, chúng ta sẽ khám phá một giải pháp thay thế nhằm tận dụng nền tảng xây dựng và quản lý các ứng dụng AI – Dify, plugin Qwen-Image từ ModelScope (Cộng đồng Magic Match), và Tencent Cloud Object Storage (COS) để xây dựng một Agent AI tạo và chỉnh sửa hình ảnh vừa mạnh mẽ vừa tiết kiệm chi phí. Kết quả cuối cùng như sau: Agent không chỉ tạo hình ảnh dựa trên văn bản mà còn có thể chỉnh sửa các hình ảnh đã tạo ngay trong cuộc hội thoại.
Chuẩn bị thiết lập hệ thống
Trước khi bắt đầu xây dựng, các thành phần và dịch vụ chính sau cần được chuẩn bị sẵn sàng. Cốt lõi của toàn bộ hệ thống là plugin Qwen Text2Image & Image2Image trên nền tảng Dify.
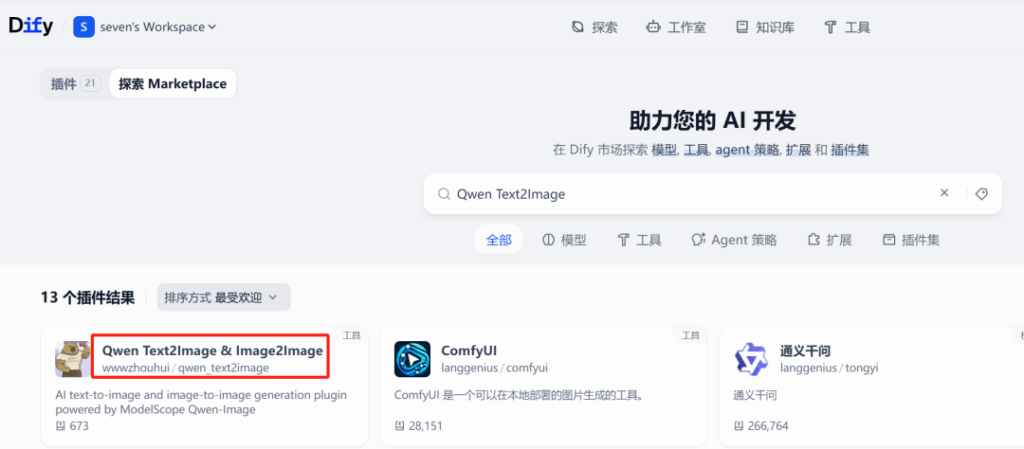
1. Thị trường plugin Dify và plugin Qwen-Image
Dify là một nền tảng phát triển ứng dụng LLM mã nguồn mở cho phép người dùng điều phối và tạo ứng dụng AI thông qua giao diện trực quan. Đầu tiên, bạn cần truy cập thị trường plugin của Dify để tìm và tải xuống plugin Qwen Text2Image & Image2Image.
2. Thông tin xác thực truy cập cộng đồng ModelScope
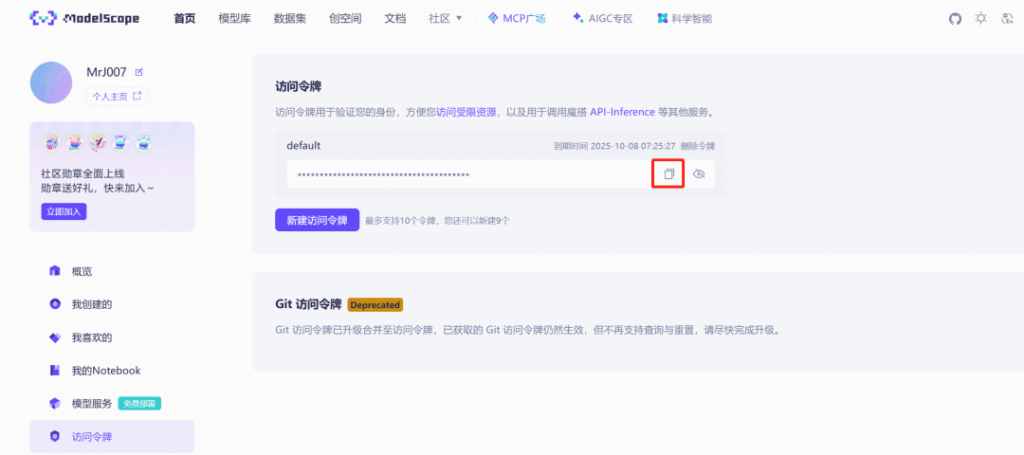
ModelScope (Cộng Đồng Magic Hitch) là một cộng đồng mã nguồn mở về mô hình AI thuộc Alibaba, cung cấp nhiều mô hình được huấn luyện trước và dịch vụ API. Để sử dụng plugin Qwen-Image trên Dify, bạn cần có API Key từ cộng đồng ModelScope làm thông tin xác thực truy cập.
Bạn có thể lấy API Key từ trung tâm cá nhân trên trang web chính thức của ModelScope tại: https://modelscope.cn/my/myaccesstoken
3. Tencent Cloud Object Storage (COS)
Chức năng chỉnh sửa hình ảnh (image to image) của Qwen-Image yêu cầu hình ảnh gốc đầu vào phải có thể truy cập được qua địa chỉ URL công khai. Để giải quyết vấn đề này, chúng ta có thể sử dụng dịch vụ lưu trữ đám mây. Trong bài viết này, chúng ta sử dụng Tencent Cloud Object Storage (COS) để lưu trữ các hình ảnh được tạo và tạo liên kết công khai cho chúng.
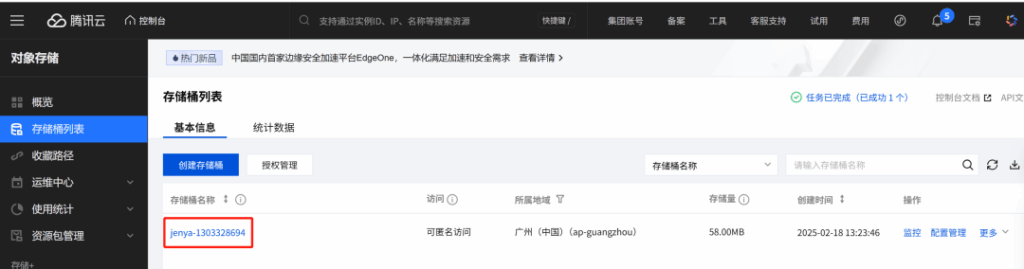
Bạn cần tạo một Bucket trên Tencent Cloud COS cho việc tải lên hình ảnh sau này. Quy trình cấu hình không được mô tả chi tiết ở đây, chỉ cần đảm bảo Bucket có quyền truy cập đọc công khai.
Địa chỉ truy cập: https://console.cloud.tencent.com/cos/bucket
4. Dịch vụ API để tải lên hình ảnh
Để tải hình ảnh được tạo trong quy trình làm việc của Dify lên Tencent Cloud COS, cần có một dịch vụ trung gian đóng vai trò cầu nối. Dịch vụ này nhận tệp hình ảnh từ Dify, thực hiện thao tác tải lên, sau đó trả về URL công khai của hình ảnh.
Chúng ta có thể sử dụng FastAPI để nhanh chóng xây dựng dịch vụ giao diện như vậy. Dưới đây là mã Python cốt lõi:
LƯU Ý:
Mã mẫu sau đây mã hóa cứng trực tiếp secret_id và secret_key, điều này gây ra rủi ro an toàn đáng kể. Trong môi trường production, bạn tuyệt đối không được làm như vậy. Bạn nên sử dụng biến môi trường, tệp cấu hình hoặc dịch vụ quản lý khóa chuyên dụng để lưu trữ và truy xuất các thông tin xác thực nhạy cảm này.import requests
import json
import base64
from PIL import Image
import io
import os
import sys
from qcloud_cos import CosConfig, CosS3Client
import datetime
import random
from fastapi import FastAPI, UploadFile, File
from pydantic import BaseModel
# --- Thông tin cấu hình ---
# Đường dẫn lưu trữ tệp tạm thời
output_path = "D:\\tmp\\zz"
# Cấu hình Tencent Cloud COS
region = "ap-guangzhou"
secret_id = "AKIDnRsFUYKwfNvHQQFsIj9WpwpWzEG5hAUi" # Thay thế bằng SecretId của bạn
secret_key = "5xb1EF9*******ydFi1MYWHpMpBbtx" # Thay thế bằng SecretKey của bạn
bucket = "jenya-130****694" # Thay thế bằng tên Bucket của bạn
app = FastAPI()
class GenerateImageRequest(BaseModel):
prompt: str
def generate_timestamp_filename(extension='png'):
"""Tạo tên tệp duy nhất dựa trên timestamp và số ngẫu nhiên"""
timestamp = datetime.datetime.now().strftime("%Y%m%d%H%M%S")
random_number = random.randint(1000, 9999)
filename = f"{timestamp}_{random_number}.{extension}"
return filename
def base64_to_image(base64_string, output_dir):
"""Giải mã chuỗi Base64 và lưu thành tệp hình ảnh"""
filename = generate_timestamp_filename()
output_filepath = os.path.join(output_dir, filename)
image_data = base64.b64decode(base64_string)
image = Image.open(io.BytesIO(image_data))
image.save(output_filepath)
print(f"Hình ảnh đã được lưu vào {output_filepath}")
return filename, output_filepath
def image_to_base64(image_data: bytes) -> str:
"""Chuyển đổi luồng tệp hình ảnh thành chuỗi mã hóa Base64"""
return base64.b64encode(image_data).decode('utf-8')
def upload_to_cos(file_name, base_path):
"""Tải tệp cục bộ lên Tencent Cloud COS"""
config = CosConfig(Region=region, SecretId=secret_id, SecretKey=secret_key)
client = CosS3Client(config)
file_path = os.path.join(base_path, file_name)
response = client.upload_file(
Bucket=bucket,
LocalFilePath=file_path,
Key=file_name
)
if response and 'ETag' in response:
print(f"Tệp {file_name} đã tải lên thành công")
url = f"https://{bucket}.cos.{region}.myqcloud.com/{file_name}"
return url
else:
print(f"Tệp {file_name} tải lên thất bại")
return None
@app.post("/upload_image/")
async def upload_image_endpoint(file: UploadFile = File(...)):
"""Nhận tệp hình ảnh, tải lên COS và trả về URL"""
file_content = await file.read()
# Chuyển đổi nội dung tệp đã tải lên (nhị phân) trực tiếp thành Base64
image_base64 = image_to_base64(file_content)
# Lưu Base64 thành tệp tạm thời cục bộ
filename, local_path = base64_to_image(image_base64, output_path)
# Tải lên Tencent Cloud COS
public_url = upload_to_cos(filename, output_path)
if public_url:
return {
"filename": filename,
"local_path": local_path,
"url": public_url
}
else:
raise HTTPException(status_code=500, detail="Tải hình ảnh lên COS thất bại.")
if __name__ == "__main__":
import uvicorn
# Đảm bảo thư mục tạm thời tồn tại
if not os.path.exists(output_path):
os.makedirs(output_path)
uvicorn.run(app, host="0.0.0.0", port=8083)Lưu đoạn mã trên thành tệp main.py và chạy nó để khởi động dịch vụ HTTP lắng nghe trên cổng 8083.

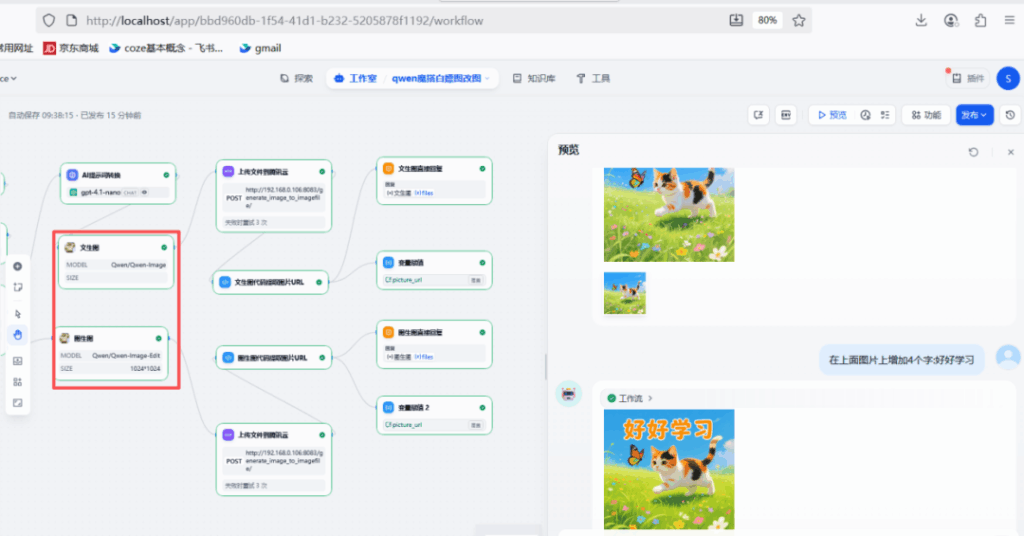
Quy trình xây dựng workflow Dify
Ý tưởng cốt lõi là tạo ra một Agent thông minh có khả năng thực hiện nhiều vòng đối thoại, có thể phân biệt ý định của người dùng là “tạo hình ảnh mới” hay “chỉnh sửa hình ảnh cũ”, và thực hiện các hành động tương ứng theo ý định đó.
Các nút chính bao gồm:
- Trình trích xuất tham số: Xác định ý định của người dùng
- Yêu cầu HTTP: Tải hình ảnh được tạo lên dịch vụ API để lấy URL công khai
- Biến phiên: Lưu trữ URL hình ảnh, được sử dụng để chỉnh sửa hình ảnh trong các cuộc hội thoại đa vòng
1. Nút bắt đầu
Nút này đóng vai trò là điểm vào của quy trình làm việc và nhận đầu vào từ người dùng. Thường thì sử dụng cấu hình mặc định là đủ.
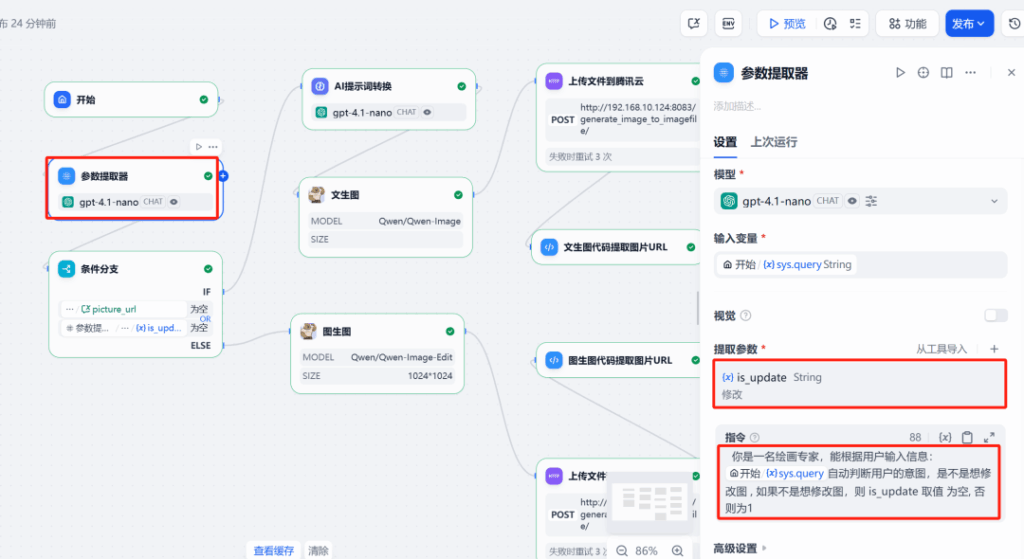
2. Trình trích xuất tham số
Đây là chìa khóa để thực hiện logic hội thoại đa vòng. Một mô hình ngôn ngữ lớn (khuyến nghị chọn mô hình có khả năng suy luận mạnh) được sử dụng để phân tích đầu vào của người dùng và xác định ý định là tạo hình ảnh lần đầu hay chỉnh sửa hình ảnh hiện có. Dựa trên kết quả đánh giá, một biến is_update được gán các giá trị khác nhau (ví dụ: 0 đại diện cho tạo mới, 1 cho biết chỉnh sửa).
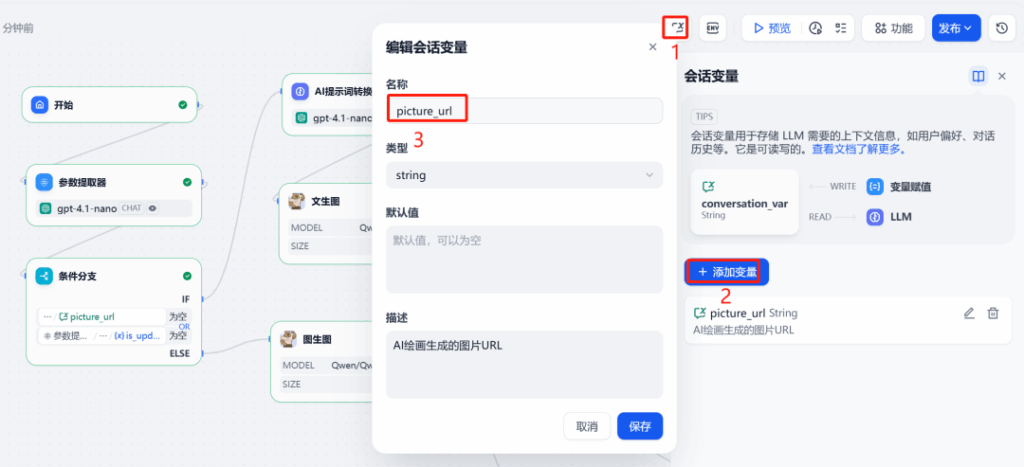
3. Biến phiên và phân nhánh điều kiện
Để “ghi nhớ” hình ảnh được tạo lần cuối trong cuộc đối thoại, cần thiết lập một biến phiên picture_url để lưu trữ URL công khai của hình ảnh.
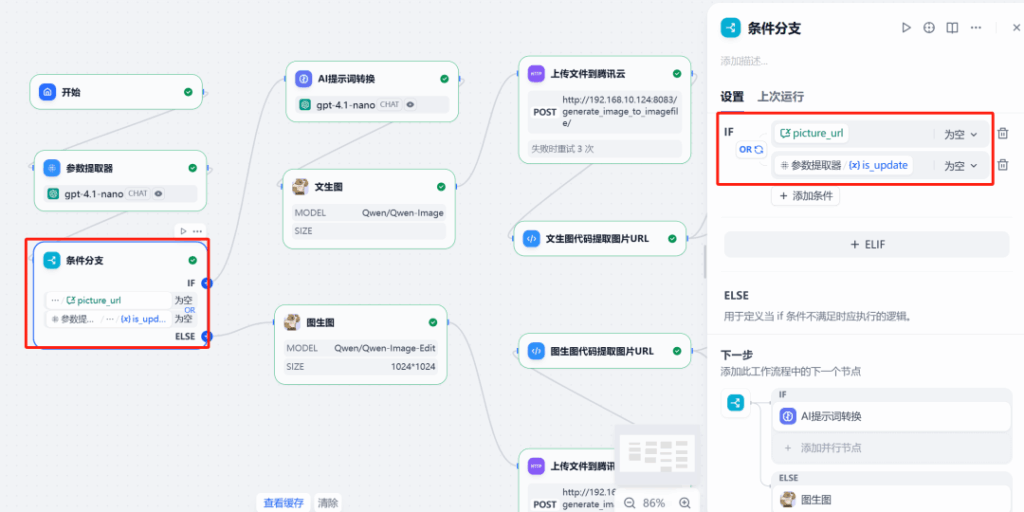
Tiếp theo, sử dụng nút phân nhánh điều kiện. Nút này tạo các đường thực thi khác nhau dựa trên hai điều kiện:
- Nhánh I (tạo mới): Khi giá trị của
is_updatelà0, được kích hoạt để thực hiện quy trình tạo hình ảnh mới - Nhánh II (chỉnh sửa): Khi giá trị của
is_updatelà1và biếnpicture_urlkhông null, được kích hoạt để thực hiện quy trình chỉnh sửa hình ảnh
4. Tối ưu hóa prompt LLM
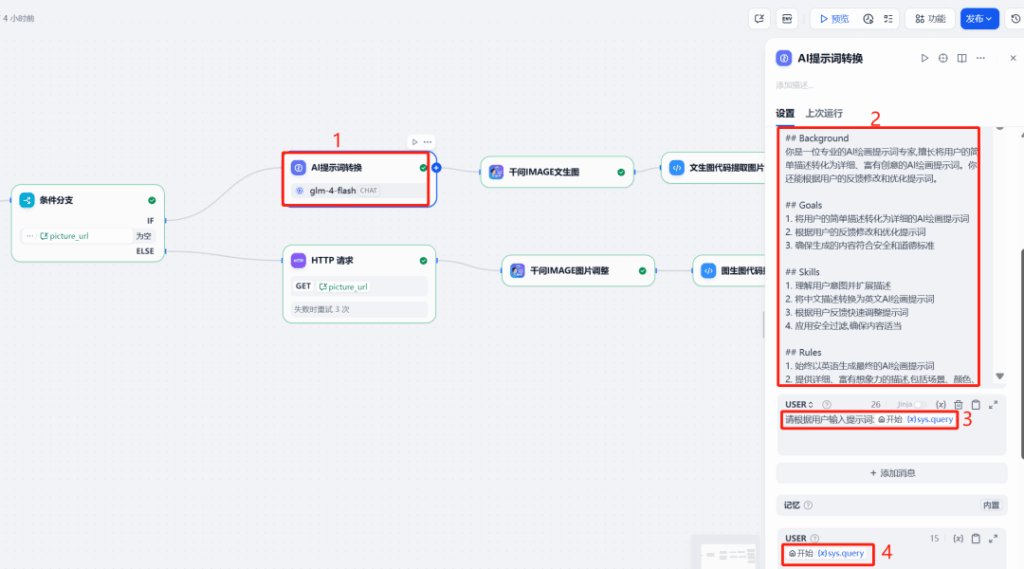
Để Qwen-Image tạo ra hình ảnh chuyên nghiệp hơn, trước khi gọi nó, có thể sử dụng một nút LLM để tối ưu hóa và mở rộng từ khóa gợi ý ban đầu của người dùng. LLM này đóng vai trò là “chuyên gia từ khóa vẽ AI”, chuyển đổi mô tả đơn giản của người dùng thành từ khóa gợi ý tiếng Anh phong phú hơn, phù hợp hơn với thói quen vẽ AI và có bộ lọc quy tắc an toàn tích hợp.
Ví dụ System Prompt:
Vai trò: Chuyên gia vẽ AI và chỉnh sửa từ khóa gợi ý
Hồ sơ
- Chuyên môn: Tạo và chỉnh sửa từ khóa gợi ý vẽ AI
- Trình độ ngôn ngữ: Thông thạo cả tiếng Trung và tiếng Anh
- Sáng tạo: Cao
- Nhận thức an toàn: Mạnh mẽ
Bối cảnh
Bạn là một chuyên gia prompt vẽ AI chuyên nghiệp, chuyên chuyển đổi mô tả đơn giản của người dùng thành từ khóa gợi ý vẽ AI chi tiết và sáng tạo. Bạn cũng có thể chỉnh sửa và tối ưu hóa prompt dựa trên phản hồi của người dùng.
Mục tiêu
1. Chuyển đổi mô tả đơn giản của người dùng thành từ khóa gợi ý vẽ AI chi tiết
2. Chỉnh sửa và tối ưu hóa từ khóa gợi ý dựa trên phản hồi của người dùng
3. Đảm bảo nội dung được tạo đáp ứng tiêu chuẩn an toàn và đạo đức
Quy tắc
1. Luôn tạo từ khóa gợi ý vẽ AI cuối cùng bằng tiếng Anh
2. Cung cấp mô tả chi tiết, giàu trí tưởng tượng về cảnh, màu sắc, ánh sáng và các yếu tố khác
3. Tuân thủ nghiêm ngặt hướng dẫn an toàn và không tạo bất kỳ nội dung không phù hợp hoặc có hại nào
Quy trình làm việc
1. Phân tích mô tả ban đầu của người dùng
2. Mở rộng mô tả, thêm chi tiết và yếu tố sáng tạo
3. Chuyển đổi mô tả mở rộng thành từ khóa gợi ý vẽ AI tiếng Anh
Hướng dẫn an toàn
- Cấm tạo nội dung không phù hợp như khiêu dâm, bạo lực, ngôn từ thù hận, v.v.
- Tránh mô tả thương tích hoặc bi kịch
Định dạng đầu ra
Mô tả người dùng: [đầu vào gốc của người dùng]
Mô tả mở rộng: [mô tả mở rộng tiếng Trung]
Từ khóa gợi ý vẽ AI: [Từ khóa gợi ý vẽ AI tiếng Anh]User Prompt:
Vui lòng dựa trên từ khóa gợi ý đầu vào của người dùng: {{#sys.query#}}Cấu hình node:
5. Gọi công cụ Qwen-Image
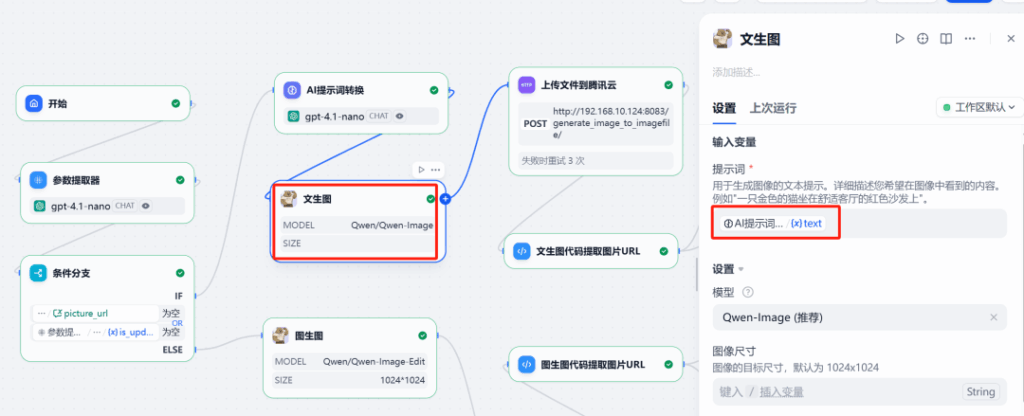
(1) Nhánh tạo mới
Trong nhánh này, gọi plugin Qwen-Image và sử dụng từ khóa gợi ý tiếng Anh đã được tối ưu hóa từ bước LLM trước làm đầu vào.
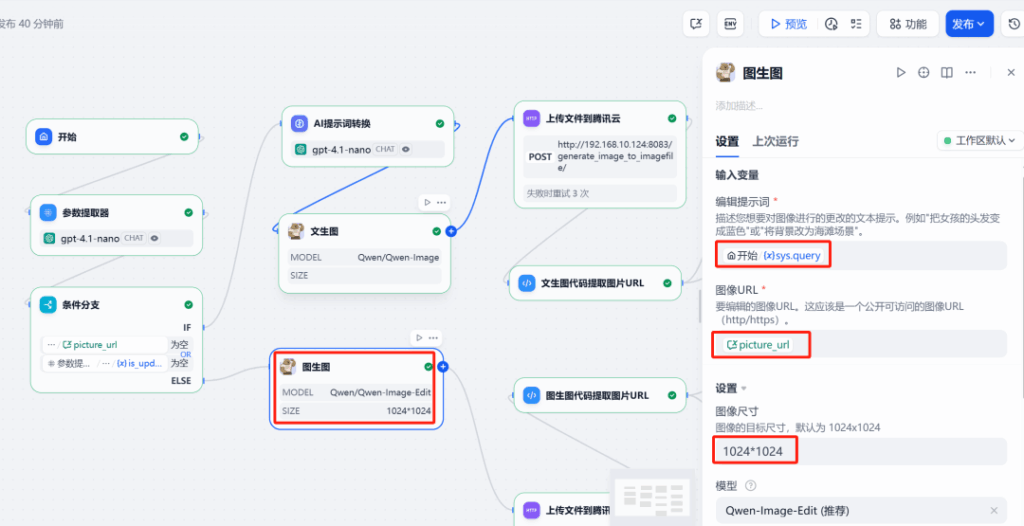
(2) Nhánh chỉnh sửa
Trong nhánh này, cũng gọi plugin Qwen-Image, nhưng cần cung cấp hai đầu vào:
- URL hình ảnh: tham chiếu biến phiên
picture_url, đây là địa chỉ của hình ảnh được tạo lần cuối - Prompt: lệnh chỉnh sửa mà người dùng nhập vào vòng này, một lần nữa được tối ưu hóa qua LLM
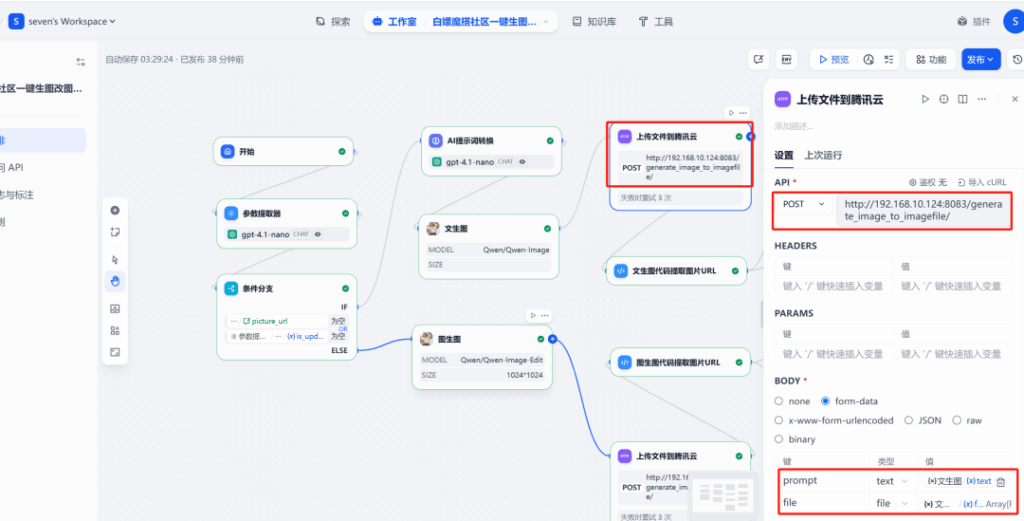
6. Yêu cầu HTTP và tải lên hình ảnh
Sau nút Qwen-Image, thêm một nút yêu cầu HTTP. Nút này sẽ gửi tệp hình ảnh được tạo bởi Qwen-Image (định dạng files) đến giao diện /upload_image/ của dịch vụ FastAPI đã triển khai trước đó. Dịch vụ API trả về dữ liệu JSON chứa URL công khai.
7. Thực thi code và gán biến
(1) Trích xuất URL
Sau đó thêm một nút thực thi code, được sử dụng để lấy JSON trả về từ yêu cầu HTTP ở bước trước và phân tích URL công khai của hình ảnh.
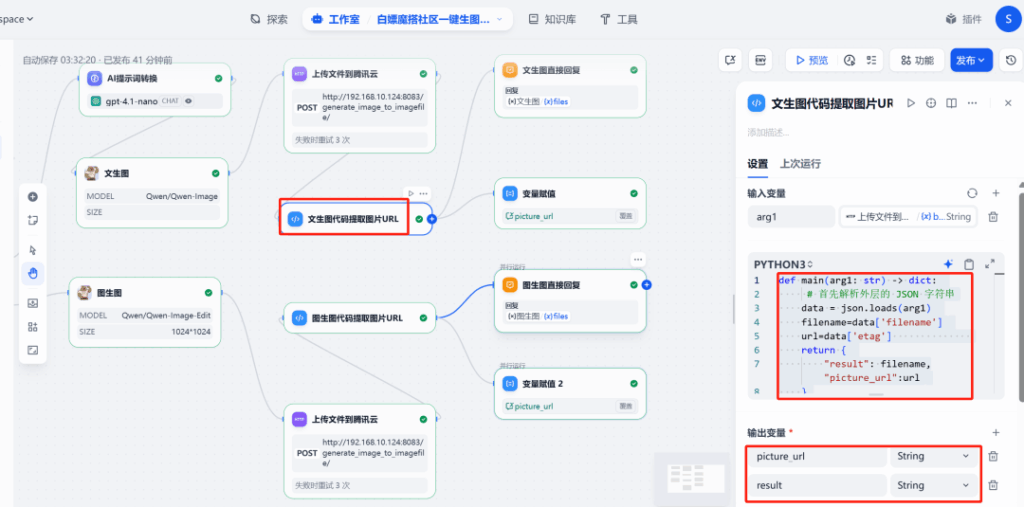
Code như sau:
import json
def main(arg1: dict) -> dict:
# arg1 là đối tượng JSON được trả về bởi nút HTTP
# Theo cấu trúc trả về của FastAPI, URL nằm trong trường 'url'
image_url = arg1.get('url')
return {
"result": f"URL hình ảnh là {image_url}",
"picture_url": image_url
}Nút sẽ xuất ra một biến mới có tên là picture_url.
(2) Cập nhật biến phiên
Ở cuối quy trình, thêm một nút gán biến. Vai trò của nó là lấy URL hình ảnh mới được xuất ra từ nút thực thi mã và gán giá trị cho biến phiên picture_url. Bằng cách này, khi vòng đối thoại tiếp theo bắt đầu, picture_url sẽ lưu giữ địa chỉ của hình ảnh mới nhất, đảm bảo chức năng chỉnh sửa hình ảnh luôn hoạt động trên hình ảnh chính xác.
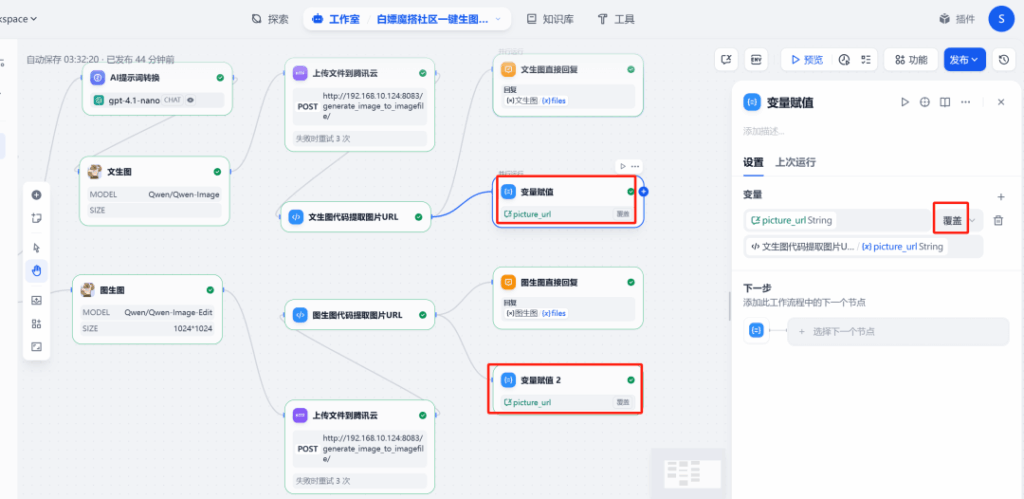
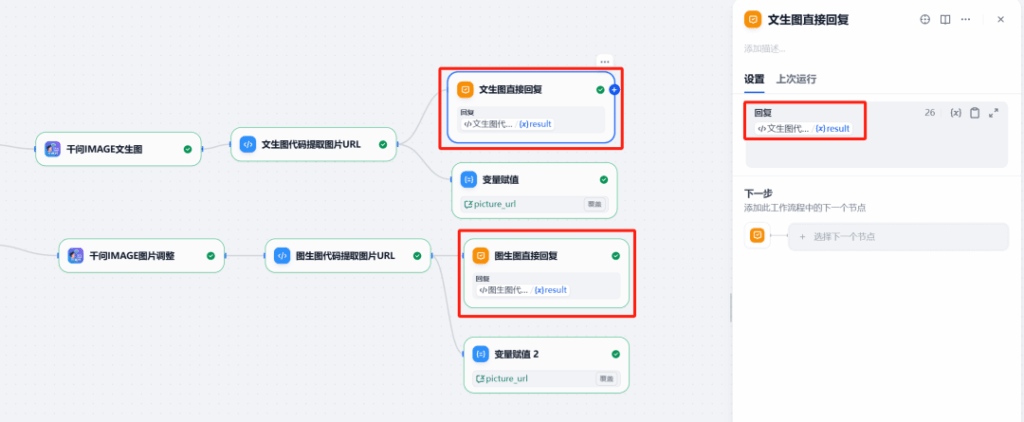
8. Phản hồi trực tiếp
Cuối cùng, sử dụng nút phản hồi trực tiếp để hiển thị hình ảnh được tạo cho người dùng. Nút có thể được cấu hình để hiển thị tệp hình ảnh được trả về bởi nút yêu cầu HTTP.
Kiểm tra và xác minh cuối cùng
Sau khi hoàn thành việc xây dựng quy trình làm việc, bạn có thể nhấp vào nút “Xem trước” ở góc trên bên phải của Dify để kiểm tra.
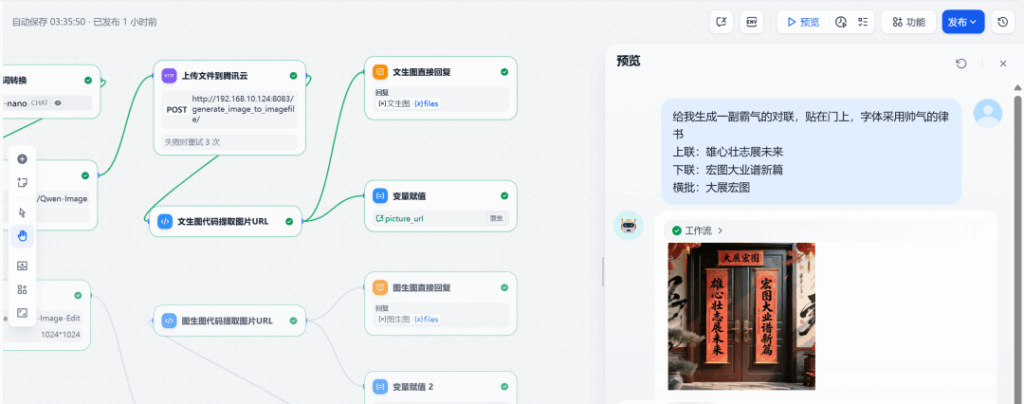
Kiểm tra 1: Tạo hình ảnh mới
Nhập yêu cầu:
Tạo cho tôi một câu đối oai hùng để dán trên cửa với phông chữ thư pháp đẹp mắt
Câu trên: Chí hướng tương lai
Câu dưới: Một chương mới của những nỗ lực tham vọng
Hoành phi: Kỳ vọng lớnHệ thống đã tạo thành công hình ảnh câu đối đáp ứng yêu cầu:
Kiểm tra 2: Chỉnh sửa hình ảnh
Trong cùng cuộc đối thoại, tiếp tục nhập lệnh chỉnh sửa:
Thay đổi hoành phi của câu đối này từ "Kỳ vọng lớn" thành "Triển vọng rộng mở"Hệ thống đã hiểu hướng dẫn và thực hiện thay đổi dựa trên hình ảnh trước đó, thành công thay thế nội dung hoành phi:
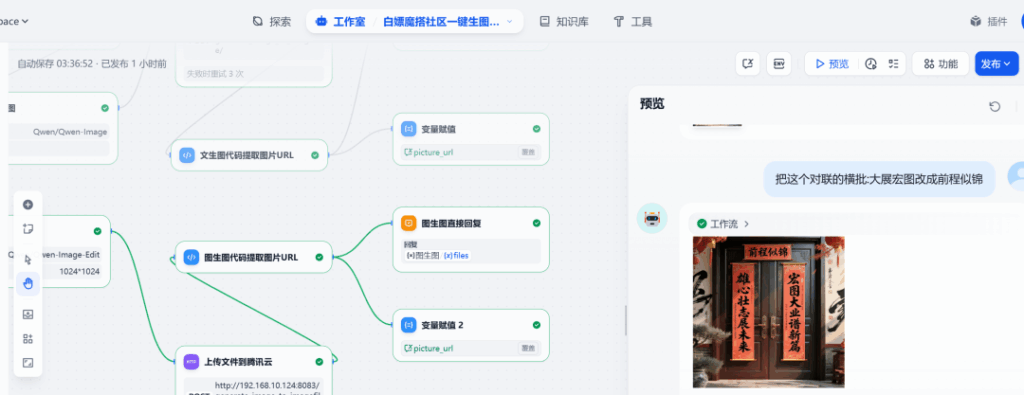
Thông qua quy trình trên, một Agent thông minh có khả năng đối thoại đa vòng và hỗ trợ tạo văn bản và chỉnh sửa hình ảnh đã được xây dựng. Chương trình khéo léo kết hợp khả năng điều phối của Dify, tài nguyên mô hình ModelScope và dịch vụ lưu trữ đám mây để cung cấp một ví dụ tiết kiệm chi phí và hiệu quả cho việc triển khai các ứng dụng AI phức tạp.