10 AI model (open-source) đáng thử cho Home Lab
Mình thực sự rất thích thú khi được trải nghiệm rất nhiều mô hình AI mới và thú vị trong năm 2025. Hiện nay có quá nhiều lựa chọn tuyệt vời để chúng ta lựa chọn. Ai mà ngờ được rằng đến thời điểm này chúng ta lại có nhiều mô hình khác nhau từ nhiều nhà cung cấp đến vậy? Việc chạy AI cục bộ và riêng tư giờ đây đã dễ dàng hơn bao giờ hết, nhờ vào các giải pháp như Ollama và OpenWebUI. Mình muốn chia sẻ một danh sách chọn lọc gồm 10 mô hình mà mình nghĩ vừa phù hợp vừa là những lựa chọn tuyệt vời cho môi trường home lab, cho dù bạn đang tìm kiếm các mô hình chatbot đa dụng, trợ giúp về code DevOps hay bất cứ điều gì khác. Hãy cùng tìm hiểu xem chúng là gì, bạn có thể sử dụng chúng cho mục đích gì, và bạn cần loại phần cứng nào về mặt VRAM để chạy chúng.
1. Gemma 3 và codegemma
Khi nói đến các mô hình mã nguồn mở bạn có thể sử dụng trong home lab của mình cho mọi loại trường hợp sử dụng, Gemma 3 thật khó để bị đánh bại. Đây là họ mô hình đa phương thức gọn nhẹ của Google, được xây dựng từ công nghệ Gemini mà Google đang sử dụng trực tuyến.
Bạn có thể sử dụng nó cho nhiều mục đích khác nhau, bao gồm văn bản, lập trình, hình ảnh và nhiều thứ khác. Nó hỗ trợ ngữ cảnh 128K và có các kích thước từ 270M (siêu nhỏ) và 1B cho đến 4B và 12B. Nhiều khả năng đối với phần cứng mà nhiều người đang chạy trong môi trường lab của mình, biến thể 4B là lựa chọn tối ưu nhất về khả năng so với tài nguyên yêu cầu. Bạn có thể sử dụng biến thể 270M cho các cuộc trò chuyện nhanh hoặc làm trợ lý chat nếu bạn muốn một thứ gì đó nhanh và đã được tinh chỉnh theo chỉ thị (instruction-tuned).
- Phù hợp cho: trợ lý gọn nhẹ, tạo mẫu RAG, thử nghiệm đa phương thức, các tác vụ đa ngôn ngữ.
- Thử trên Ollama:
gemma3:270m,gemma3:1b,gemma3:4b,gemma3:12b - VRAM (lượng tử hóa Q4):
- 270M ≈ ~2 GB
- 1B ≈ ~3–4 GB
- 4B ≈ ~6–7 GB
- 12B ≈ ~12–14 GB
codegemma
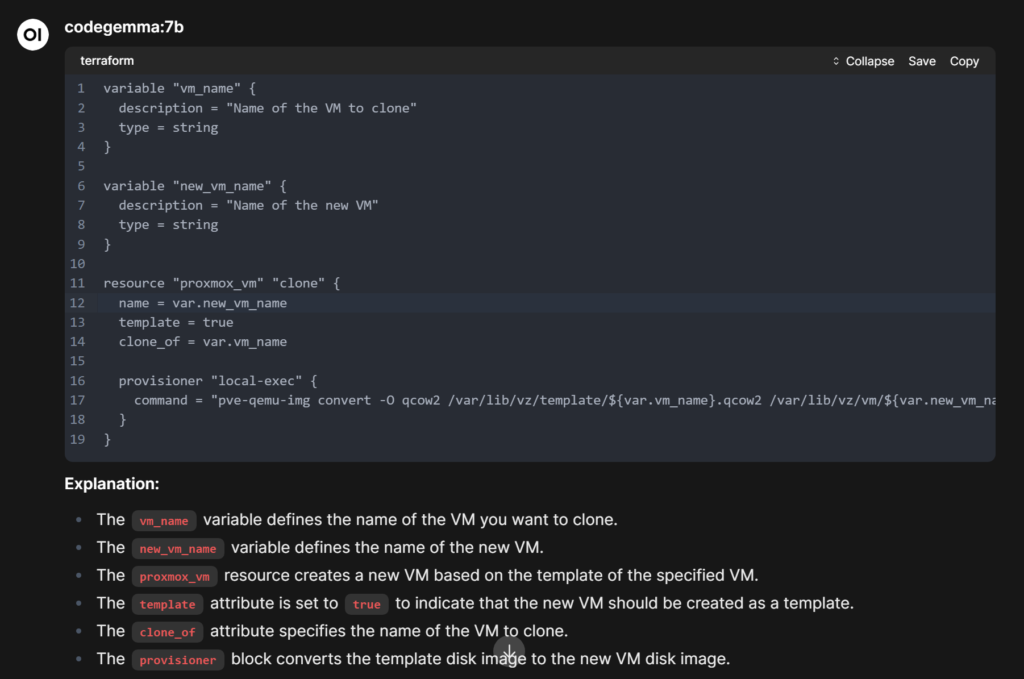
Nếu bạn đang tìm kiếm một mô hình tuyệt vời cho các tác vụ lập trình và liên quan đến DevOps trong home lab, codegemma cũng là một lựa chọn tuyệt vời. Nó tập trung nhiều hơn vào lập trình so với Gemma 3, một mô hình tổng quát hơn. Hãy xem đoạn mã Terraform mà mình đã tạo bằng codegemma:
Cách tải Gemma 3
ollama pull gemma3:270m
ollama pull gemma3:1b
ollama pull gemma3:4b
ollama pull gemma3:12b
2. Gemma 3n (hiệu quả “tương đương 2B/4B”)
Có một biến thể khác gọi là mô hình Gemma 3n nhắm đến các thiết bị còn nhẹ hơn như laptop và các thiết bị hàng ngày. Mô hình này hoạt động giống như một mô hình 2B/4B trong quá trình suy luận mặc dù có nhiều tham số tổng thể hơn ở phía sau.
Mô hình này rất tuyệt vời cho các trợ lý có chi phí tài nguyên rất thấp hoặc nếu bạn muốn đẩy các mô hình nhỏ này lên các thin client hoặc các thiết bị nhẹ khác.
- Phù hợp cho: trợ lý cục bộ siêu hiệu quả, thiết bị biên (edge devices), các agent luôn hoạt động.
- Thử trên Ollama:
gemma3n:e2b(và các tag khác trên trang) - VRAM (lượng tử hóa Q4):
- tương đương 2B ≈ ~4–5 GB
- tương đương 4B ≈ ~6–7 GB
Cách tải Gemma 3n
ollama pull gemma3n:e2b
ollama pull gemma3n:e4b3. Qwen 2.5:7b và qwen2.5-coder:7b
Mô hình Qwen 2.5 đến từ Alibaba và là một họ mô hình đa dụng giống như Gemma. Nó có hỗ trợ đa ngôn ngữ rất tốt và cửa sổ ngữ cảnh dài lên đến 128K. Mô hình này có các kích thước từ 0.5B siêu nhỏ cho đến 72B. Vì vậy, có đủ lựa chọn cho tất cả mọi người, từ những người có tài nguyên GPU rất nhỏ cho đến những người chạy nhiều GPU để xử lý mô hình 72B đầy đủ. Các mô hình Qwen 2.5 được huấn luyện trước trên bộ dữ liệu quy mô lớn mới nhất của Alibaba, bao gồm tới 18 nghìn tỷ token.
Tuy nhiên, điểm sáng của Qwen 2.5 là các mô hình 7B và 14B. Mô hình 7B là một mô hình nhanh và thiết thực, không yêu cầu nhiều hơn một card đồ họa tầm trung. Mô hình 14B có khả năng suy luận nặng hơn và vẫn có thể chạy trên một GPU tiêu dùng duy nhất.
qwen2.5-coder:7b
Phiên bản coder rất tuyệt vời cho việc tạo mã, suy luận về mã và sửa mã, bao gồm cả các tác vụ DevOps nói chung. Vì vậy, nếu bạn muốn có một mô hình tuyệt vời để giúp viết cơ sở hạ tầng dưới dạng mã (IaC) cho DevOps trong home lab của mình, đây là một lựa chọn rất tốt.
Qwen phù hợp cho:
- Phù hợp cho: trò chuyện đa ngôn ngữ, suy luận, tạo mẫu sử dụng công cụ, tóm tắt ngữ cảnh dài.
- Thử trên Ollama:
qwen2.5:4b,qwen2.5:14b(có sẵn các kích thước khác) - VRAM (lượng tử hóa Q4):
- 4B ≈ ~6–7 GB
- 14B ≈ ~12–14 GB
- 32B+ ≈ ~20 GB trở lên
Cách tải Qwen 2.5
ollama pull qwen2.5:7b
ollama pull qwen2.5:14b
ollama pull qwen2.5-coder:7b
Còn Qwen 3 thì sao?
Bạn có thể đã thấy có một phiên bản Qwen 3 cũng có sẵn trên Ollama và chắc chắn cũng nên thử nó. Lý do chúng mình vẫn nhấn mạnh vào Qwen 2.5 là vì nó đã có các bản dựng được lượng tử hóa tốt, bao gồm Q4/Q5/Q8, phổ biến rộng rãi, tải dễ dàng trong Ollama và có thể chạy mà không cần nhiều tài nguyên VRAM.
Qwen 3 rất hấp dẫn nhưng nặng hơn và mới hơn nhiều, vì vậy nó vẫn đang trong giai đoạn phát triển để sử dụng thực tế trong home lab. Các đặc điểm chính của nó là:
- Mạnh hơn Qwen 2.5 về suy luận, sử dụng công cụ và các tác vụ nhiều bước.
- Nhu cầu VRAM cao hơn ở các quy mô lớn (30B+ thực sự cần 20–24 GB+).
- Hệ sinh thái hỗ trợ vẫn đang hoàn thiện so với 2.5 (ít bản dựng lượng tử hóa và ít dự án sử dụng nó hơn).
4. Mistral 7B
Mô hình Mistral 7B là một lựa chọn thực sự tuyệt vời cho việc tuân theo chỉ thị nói chung và nó cũng rất tuyệt để hỗ trợ lập trình. Đây là một trong những biến thể phổ biến nhất trong thư viện Ollama và có các biến thể như instruct. Đây là một mô hình tốt để lựa chọn nếu bạn muốn có sự cân bằng giữa tốc độ, chất lượng và không yêu cầu nhiều tài nguyên về mặt VRAM.
- Phù hợp cho: trò chuyện chung, tóm tắt, hỗ trợ lập trình nhẹ, demo RAG.
- Thử trên Ollama:
mistral:instructhoặcmistral:latest - VRAM (lượng tử hóa Q4): ~7–9 GB
Cách tải Mistral 7B
ollama pull mistral:7b
5. Llama 3
Llama 3 là mô hình mã nguồn mở của Meta có các kích thước 8B và 70B có thể tìm thấy trong thư viện Ollama. Nếu bạn có một thiết bị home lab với một GPU duy nhất, tùy chọn 8B là lựa chọn phù hợp. Tùy chọn 70B sẽ cần một cấu hình đa GPU khá “xa xỉ” để chạy một cách thỏa đáng mà không phải chờ đợi mãi mãi.
- Phù hợp cho: trợ lý đa năng, hỏi đáp tài liệu, các tác vụ lập trình nhỏ.
- Thử trên Ollama:
llama3:8b(70B tồn tại nhưng rất nặng) - VRAM (lượng tử hóa Q4):
- 8B ≈ ~8–10 GB
- 70B ≈ vượt xa khả năng của card 24 GB đơn, có thể sẽ cần các card đa Quadro chuyên dụng.
Cách tải Llama 3
ollama pull llama3:8b6. Llama 3.2 (mô hình nhỏ 1B/3B)
Một mô hình thực sự thú vị khác từ Meta là Llama 3.2. Biến thể này bổ sung các mô hình nhỏ gọn 1B và 3B được tối ưu hóa cho các thứ như đối thoại và các trường hợp sử dụng đa ngôn ngữ. Những mô hình này cực kỳ dễ chạy trên phần cứng GPU tối thiểu hoặc thậm chí cả CPU cấu hình thấp hơn. Bạn có thể sử dụng các mô hình này cho các trợ lý nhúng cho công cụ phát triển, bảng điều khiển home lab hoặc các tác vụ tự động hóa nhỏ.
- Phù hợp cho: chatbot có độ trễ thấp, trợ lý lập trình CLI, agent biên, trợ giúp đa ngôn ngữ.
- Thử trên Ollama:
llama3.2:1b,llama3.2:3b - VRAM (lượng tử hóa Q4):
- 1B ≈ ~2–3 GB
- 3B ≈ ~5–6 GB
Cách tải Llama 3.2
ollama pull llama3.2:1b
ollama pull llama3.2:3b7. DeepSeek-R1 (tập trung vào suy luận)
DeepSeek đã làm đảo lộn thế giới các mô hình AI mã nguồn mở. DeepSeek R1 là một họ mô hình suy luận mã nguồn mở với các mô hình từ rất nhỏ đến rất lớn. Bạn có thể chọn giữa 7B/8B/14B là những mô hình thực tế cho home lab. Đây là những mô hình “tư duy”, và bạn sẽ tìm thấy chúng trong các tag. Nếu bạn muốn thử nghiệm với các prompt kiểu “chuỗi tư duy” (chain-of-thought), quy trình làm việc trên nháp (scratchpad) hoặc các tác vụ đòi hỏi suy luận nặng, DeepSeek-R1 sẽ vượt trội ở những lĩnh vực này.
- Phù hợp cho: suy luận nhiều bước, lập kế hoạch, khung sườn sử dụng công cụ, prompt phân tích.
- Thử trên Ollama: bắt đầu với
deepseek-r1:7bhoặcdeepseek-r1:14b(xem Tags để biết các tùy chọn) - VRAM (lượng tử hóa Q4):
- 8B ≈ ~8–10 GB
- 14B ≈ ~12–14 GB
Cách tải DeepSeek-R1
ollama pull deepseek-r1:7b
ollama pull deepseek-r1:14b
8. OLMo 2 (AI2)
Với OLMo 2, bạn có một mô hình huấn luyện hoàn toàn mở và minh bạch có thể có ở kích thước 7B và 13B. Hiệu suất của nó rất giống với các mô hình mã nguồn mở/trọng số mở có kích thước tương tự khác. Đây là một mô hình thực sự tốt nếu bạn quan tâm đến tính thân thiện với nghiên cứu. Ngoài ra, bạn còn có được khả năng lặp lại tốt và hành vi được tinh chỉnh theo chỉ thị.
- Phù hợp cho: các thí nghiệm có thể tái tạo, các đường cơ sở RAG, bot tài liệu.
- Thử trên Ollama:
olmo2:7b,olmo2:13b - VRAM (lượng tử hóa Q4):
- 7B ≈ ~8–10 GB
- 13B ≈ ~12–14 GB
Cách tải OLMo 2
ollama pull olmo2:7b
ollama pull olmo2:13b
9. Phi-3 / Phi-3.5 từ Microsoft
Đây là một mô hình mình đã mày mò khá lâu trong LM Studio. Tuy nhiên, nó chắc chắn là một trong những mô hình mình giữ trong danh sách đã tải xuống với Ollama. Các mô hình Phi của Microsoft nhỏ và cực kỳ hiệu quả với việc tinh chỉnh theo chỉ thị. Phi-3 Mini 3.8B chạy trên các GPU công suất rất thấp và thậm chí chỉ với suy luận trên CPU. Phi-3.5 mở rộng ngữ cảnh lên 128K và cũng tăng chất lượng phản hồi. Những mô hình này rất tuyệt vời cho các trợ lý AI và các tác vụ tự động hóa nhẹ mà bạn có thể muốn thử nghiệm trong home lab của mình.
- Phù hợp cho: trợ lý chat nhanh, dọn dẹp dữ liệu hàng loạt, các agent web nhỏ, sử dụng năng lượng thấp.
- Thử trên Ollama:
phi3:mini,phi3:medium, hoặcphi3.5:mini - VRAM (lượng tử hóa Q4):
- Mini 3.8B ≈ ~4–6 GB
- Medium 14B ≈ ~12–14 GB
Cách tải Phi-3 và Phi-3.5
ollama pull phi3:mini
ollama pull phi3:medium
ollama pull phi3.5:mini10. LLaVA v1.6
LLaVA là một sự kết hợp kinh điển giữa bộ mã hóa thị giác (vision encoder) và một LLM cho các cuộc trò chuyện có nhận biết hình ảnh mà bạn có thể muốn sử dụng. Với phiên bản v1.6 trong Ollama, bạn có thể thử nghiệm các tác vụ như mô tả ảnh chụp màn hình bạn có thể chụp, hoặc trích xuất văn bản từ giao diện người dùng. Bạn cũng có thể sử dụng nó để trả lời các câu hỏi về hình ảnh mà bạn muốn nó kiểm tra. Với mô hình này, bạn sẽ cần nhiều VRAM hơn so với một mô hình chỉ xử lý văn bản. Tuy nhiên, đây là một cách tuyệt vời để bắt đầu khám phá các VLM (Vision Language Models) cục bộ.
- Phù hợp cho: hỏi đáp ảnh chụp màn hình, trợ giúp tự động hóa giao diện người dùng, lấy kiến thức từ sơ đồ/hình ảnh.
- Thử trên Ollama:
llava:v1.6(có các kích thước 7B/13B/34B) - VRAM (lượng tử hóa Q4):
- 7B VLM ≈ ~12–16 GB
- các kích thước lớn hơn tăng lên nhanh chóng
Cách tải LLaVA 7b v1.6
ollama pull llava:7bBonus thêm một model nữa: SmallThinker (3B)
SmallThinker là một mô hình suy luận nhỏ gọn được tinh chỉnh từ Qwen2.5-3B-Instruct. Đây là một lựa chọn thú vị cho các thiết lập chạy chủ yếu bằng CPU hoặc có VRAM rất thấp. Bạn có thể sử dụng nó nếu muốn thử nghiệm với hành vi kiểu chuỗi tư duy (chain-of-thought). Nếu bạn muốn một trợ lý nhanh, luôn hoạt động cho các tác vụ nhỏ, đây là một mô hình đáng xem xét.
- Phù hợp cho: các agent suy luận nhỏ, thí nghiệm chỉ dùng CPU, trợ lý lập trình trên máy phát triển.
- Thử trên Ollama:
smallthinker - VRAM (lượng tử hóa Q4): ~4–5 GB
Cách tải SmallThinker
ollama pull smallthinker
Chọn kích thước phù hợp với phần cứng của bạn
Chỉ là một lưu ý, bạn có thể làm được RẤT NHIỀU thứ với các mô hình AI cục bộ ngay cả với phần cứng rất khiêm tốn.
Để kiểm tra nhanh, bạn có thể chạy một mô hình lớp 1-3B trên gần như mọi thứ. Các mô hình từ 4–8B sẽ hoạt động tốt trên 8–10 GB VRAM. Các mô hình 12–14B thích hợp với 12–16 GB VRAM. Còn các mô hình 30B+ thực sự cần 20–24 GB trở lên. Nếu bạn chỉ dùng CPU, mọi thứ sẽ chạy, nhưng bạn sẽ cảm thấy khá “khó thở” khi chạy mô hình trên ~7B trừ khi bạn chấp nhận ngữ cảnh rất ngắn.
So sánh các mô hình trong bảng
| Họ mô hình | Thẻ Ollama ví dụ | Điểm mạnh | Trường hợp sử dụng trong home-lab | VRAM gần đúng (Q4) |
| Gemma 3 | gemma3:270m gemma3:1b gemma3:4b gemma3:12b | Đa phương thức, ngữ cảnh 128K, đa ngôn ngữ | Trợ lý chung, RAG, thị giác+văn bản | 270M ~2 GB, 1B ~3–4 GB, 4B ~6–7 GB, 12B ~12–14 GB |
| Gemma 3n | gemma3n:e2b (và các loại khác) | Thiết kế cho thiết bị biên; kích hoạt chọn lọc | Trợ lý siêu hiệu quả, laptop/máy tính bảng | e2b ~4–5 GB, e4b ~6–7 GB |
| Qwen 2.5 | qwen2.5:4b qwen2.5:14b (nhiều kích cỡ) | Đa ngôn ngữ mạnh + ngữ cảnh dài | Chat, tóm tắt, sử dụng công cụ | 4B ~6–7 GB, 14B ~12–14 GB, 32B+ ~20 GB+ |
| Mistral 7B | mistral:instruct | Nhanh, được tinh chỉnh tốt ở mức 7B | Chat chung, trợ giúp lập trình | ~7–9 GB |
| Llama 3 | llama3:8b | Mô hình đa dụng 8B có năng lực; hệ sinh thái lớn | Trợ lý hàng ngày, hỏi đáp tài liệu | 8B ~8–10 GB (70B nặng hơn rất nhiều) |
| Llama 3.2 | llama3.2:1b llama3.2:3b | Nhỏ, tối ưu cho đối thoại | Trợ lý CLI, bảng điều khiển, agent biên | 1B ~2–3 GB, 3B ~5–6 GB |
| DeepSeek-R1 | deepseek-r1:7b deepseek-r1:14b | Các biến thể tập trung vào suy luận | Lập kế hoạch, khung sườn sử dụng công cụ | 7–8B ~8–10 GB, 14B ~12–14 GB |
| OLMo 2 | olmo2:7b olmo2:13b | Công thức huấn luyện mở, đường cơ sở mạnh | RAG có thể tái tạo, nghiên cứu | 7B ~8–10 GB, 13B ~12–14 GB |
| Phi-3 / 3.5 | phi3:mini phi3:medium phi3.5:mini | Mô hình nhỏ hiệu quả, ngữ cảnh dài trên 3.5 | Trợ lý gọn nhẹ, tác vụ hàng loạt | Mini 3.8B ~4–6 GB, Medium 14B ~12–14 GB |
| LLaVA v1.6 | llava:v1.6 (7B/13B/34B) | Thị giác + ngôn ngữ | Hỏi đáp ảnh chụp màn hình, chat nhận biết hình ảnh | 7B VLM ~12–16 GB; lớn hơn |
Có rất nhiều mô hình khác nhau phù hợp cho nhiều dự án khác nhau. Nếu bạn có 8–10 GB VRAM, bạn có thể bắt đầu với những mô hình như mistral:7b, llama3:8b, hoặc qwen2.5:4b. Nếu bạn có 12–16 GB, điều này sẽ cho phép bạn chạy những mô hình như gemma3:12b, qwen2.5:14b, olmo2:13b, và DeepSeek-R1 cỡ trung bình. Đối với phần cứng cấp laptop, có những mô hình rất nhỏ như llama3.2:1b/3b, phi3:mini, smallthinker, và gemma3:270m là hoàn hảo. Và nếu bạn muốn thử nghiệm với thị giác, llava là cách dễ nhất để thực hành đa phương thức trong một home lab. Hãy cho mình biết trong phần bình luận bạn đang sử dụng mô hình nào và cho những mục đích gì nhé.
Chia sẻ: Brandon Lee