5 kỹ thuật xử lý lỗi trong n8n workflows giúp sản phẩm vận hành ổn định
Khi xây dựng hệ thống tự động hóa với n8n, một trong những yếu tố quyết định hệ thống có thực sự “production-ready” hay không chính là khả năng xử lý lỗi hiệu quả. Đảm bảo workflow không dừng lại giữa chừng, các lỗi được log và thông báo kịp thời, các tác vụ quan trọng luôn được thực hiện đúng tiến độ – đó là nền tảng cho vận hành tự động ổn định, đáng tin cậy. Trong bài viết này, mình sẽ chia sẻ 5 kỹ thuật xử lý lỗi trong n8n workflows mà bất cứ ai muốn đưa tự động hóa vào sản xuất thực thụ đều phải nắm vững. Những kinh nghiệm này được đúc rút từ chính workflow ví dụ đi kèm, với mục tiêu tối ưu trải nghiệm, giảm thiểu rủi ro, và tăng tính tự chủ cho hệ thống của bạn.
Hiểu thế nào là một workflow “production-ready” trong n8n
Trước khi đi sâu vào các kỹ thuật, mình muốn lưu ý về khái niệm workflow “production-ready” trong môi trường n8n. Trong giai đoạn thử nghiệm, bạn thường thao tác trực tiếp trên workflows ở trạng thái “inactive”: chạy thử, chỉnh sửa, quan sát dòng dữ liệu và phản hồi ngay. Nhưng khi đã “bật công tắc” chuyển sang chế độ “active”, workflow gần như đã hòa vào luồng công việc chính thức – nhận trigger thực, thực hiện hành động thật lên các công cụ, dữ liệu trong hệ thống.
Ở môi trường production này, mọi sai sót, sự cố hay bất kỳ lỗi phát sinh nào đều có thể dẫn tới hậu quả rất khó lường – như gửi sai email tới hàng ngàn khách hàng, xóa nhầm dữ liệu hoặc bỏ sót hàng loạt thông báo quan trọng. Do đó, việc chủ động xây dựng các kỹ thuật xử lý lỗi không chỉ giúp bạn yên tâm khi tự động hóa vận hành mà còn mang lại sự kiểm soát và khả năng phục hồi linh hoạt trước mọi tình huống bất ngờ.
Một workflow production-ready về mặt xử lý lỗi thường bao gồm các yếu tố sau:
- Có thông báo tự động khi xảy ra lỗi.
- Ghi log đầy đủ các trường hợp lỗi.
- Hỗ trợ retry và fallback thông minh.
- Khi thất bại, luôn đảm bảo thất bại an toàn, tránh tác động dây chuyền hoặc phá hoại dữ liệu/phép toán quy mô lớn.
- Có các “guardrail” (hàng rào bảo vệ) cho các tình huống bất ngờ hoặc đầu vào ngoài dự kiến, dựa trên quá trình ghi nhận lỗi thực tế.
Sau đây là những kỹ thuật chủ lực được thể hiện trong workflow:
Download workflow: https://romhub.io/n8n/5_Error_Handling_Techniques1. Thiết kế error workflow – bước đầu tiên không thể thiếu
Một trong những giải pháp tối quan trọng khi nói đến xử lý lỗi trong n8n workflows là xây dựng và sử dụng error workflow riêng biệt. Nguyên lý hoạt động như sau:
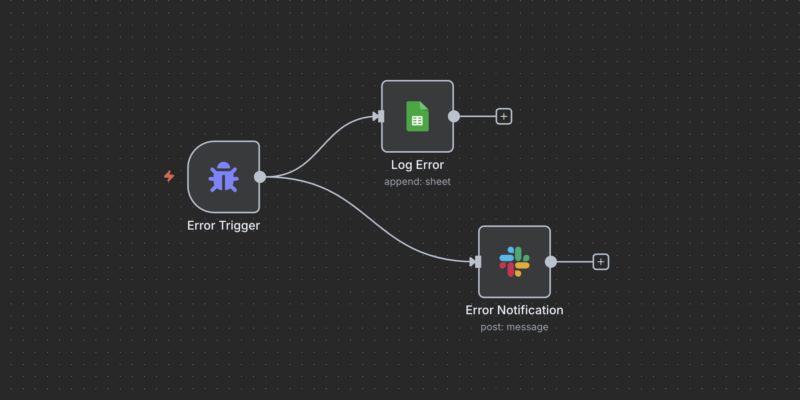
- Bạn thiết kế một workflow mới, trong đó node đầu tiên là Error Trigger.
- Trong phần cài đặt của các workflow production, bạn trỏ mục “Error Workflow” về workflow xử lý lỗi này. Khi có sự cố, nó sẽ được kích hoạt tự động.
- Trong error workflow, bạn có thể xây dựng logic tùy ý. Như trong ví dụ, workflow sẽ thực hiện đồng thời hai việc:
- Dùng node Log Error (Google Sheets) để ghi lại thông tin chi tiết về lỗi, bao gồm: Timestamp, tên workflow, URL, tên node bị lỗi và thông điệp lỗi.
- Dùng node Error Notification (Slack) để gửi một cảnh báo tức thời đến một channel cụ thể, giúp đội ngũ vận hành phát hiện vấn đề ngay lập tức.
Vì sao approach này lại cần thiết? Hãy tưởng tượng khi credentials của một tool bị hết hạn, hoặc services gặp trục trặc, nếu không có error workflow, bạn sẽ “mù tịt”, chỉ đến khi phát hiện hàng loạt records lỗi hoặc dữ liệu mất mát mới giật mình xử lý thì đã quá muộn. Việc error workflow chủ động ghi nhận lỗi và gửi cảnh báo giúp phát hiện, xác định và xử lý vấn đề kịp thời.
Một số lưu ý khi triển khai error workflow trong n8n
- Luôn trỏ tất cả các workflow production vào error workflow để đảm bảo mọi sự cố đều được quản lý tập trung.
- Tùy chỉnh nội dung message và các cột trong file log để dễ truy vết và phân tích nguyên nhân.
- Định kỳ kiểm tra lịch sử chạy của error workflow để phát hiện xu hướng, lỗi lặp lại.
2. Tận dụng kỹ thuật retry – giúp workflow không gục ngã trước các lỗi tạm thời
Trong môi trường thực tế, một số lỗi xuất hiện do lý do tạm thời: server downtime, lỗi kết nối mạng, service quá tải… Nếu workflow chỉ gặp lỗi một lần rồi dừng lại, toàn bộ quy trình sẽ bị ngưng trệ. Đó là lý do cần vận dụng kỹ thuật retry (thử lại khi thất bại).
Trong n8n, bạn có thể vào phần cài đặt của node (Settings) và bật tùy chọn Retry On Fail. Trong workflow ví dụ, kỹ thuật này được áp dụng cho node AI Agent và Send a message (Gmail). Cách cấu hình như sau:
- Bật tùy chọn “Retry on Fail”.
- Cấu hình số lần thử lại (Retries) và khoảng thời gian chờ giữa mỗi lần thử (Wait Time).
- Chỉ sau khi đã thử lại hết số lần đã định mà vẫn thất bại, workflow mới thực sự báo lỗi và kích hoạt error workflow.
Sử dụng retry vừa giúp workflow vượt qua các sự cố tạm thời vừa tránh được việc gửi hàng loạt lỗi không cần thiết đến hệ thống giám sát. Tuy nhiên, không nên lạm dụng số lần retry quá cao – dễ gây nghẽn hệ thống hoặc spam các backend services.
Cách ứng dụng retry hiệu quả
- Đối với các API thường xuyên gặp timeout, nên đặt 2-3 lần retry, mỗi lần cách nhau vài giây đến một phút.
- Đối với các tác vụ nhạy cảm (ví dụ: ghi dữ liệu database), giữ retry ở mức thấp, đổi lại chú trọng logging để không thất thoát thông tin quan trọng.
- Kết hợp retry với error workflow để vừa tự phục hồi vừa ghi nhận toàn bộ các lần thử thất bại.
3. Tích hợp fallback LLM – bí quyết “bảo hiểm” cho các automation sử dụng AI
Trong những workflow khai thác sức mạnh của các Mô hình Ngôn ngữ lớn (LLM), việc một dịch vụ AI bất ngờ gặp sự cố là điều hoàn toàn có thể xảy ra. Kỹ thuật fallback LLM sẽ giúp bạn chủ động đối phó tình huống này. Workflow mẫu đã minh họa điều này rất rõ ở node Fallback Agent:
- Node được kết nối với hai model khác nhau. Model chính là OpenRouter, trong khi model dự phòng (fallback) là Google Gemini Chat Model.
- Khi model chính (OpenRouter) gặp lỗi (ví dụ: API key sai, dịch vụ downtime, hết quota), node sẽ không dừng lại mà tự động chuyển sang sử dụng model fallback (Google Gemini).
- Để làm được điều này, bạn chỉ cần kết nối cả hai model vào cùng một agent và n8n sẽ tự động ưu tiên model ở cổng kết nối đầu tiên, sau đó chuyển sang các cổng sau nếu gặp lỗi.
Điều này cực kỳ hữu dụng ở các workflow quan trọng – nơi bạn không muốn chỉ vì một nhà cung cấp AI bị sự cố mà toàn bộ tự động hóa dừng lại. Fallback LLM không chỉ duy trì hiệu quả công việc mà còn giúp bạn giữ được trải nghiệm ổn định cho người dùng cuối.
Một số kinh nghiệm khi cấu hình fallback LLM
- Luôn kiểm thử cả hai model với đầu vào thực tế để đảm bảo logic xử lý đồng nhất và kết quả output phù hợp.
- Nếu fallback model có chất lượng thấp hơn hoặc chi phí khác biệt, hãy thiết lập hệ thống log/notify riêng biệt để phân tích các trường hợp xảy ra chuyển đổi fallback.
4. Cài đặt “continue on error” – không để workflow dừng lại vì 1 thất bại nhỏ
Đôi khi trong automation, bạn sẽ gặp các tình huống mà một hoặc vài tác vụ nhỏ gặp lỗi nhưng không đáng để toàn bộ quy trình dừng lại. Điều này đặc biệt đúng khi xử lý dữ liệu theo lô (batch processing), ví dụ như lặp qua một danh sách. Nếu không có cài đặt phù hợp, chỉ một item lỗi cũng đủ làm toàn bộ workflow dừng lại, bỏ qua tất cả các item còn lại.
Workflow ví dụ đã mô tả hai trường hợp:
- Mặc định (Stops Workflow): Node Tavily trong vòng lặp đầu tiên không có cài đặt đặc biệt. Nếu một item (ví dụ
'"nvidia"'với cặp ngoặc kép thừa) gây lỗi, cả vòng lặp sẽ dừng. - Tiếp tục khi có lỗi (Workflow Continues): Node Tavily1 trong vòng lặp thứ hai được bật tùy chọn Continue On Fail trong phần cài đặt (Settings). Giờ đây, nếu một item gây lỗi, workflow sẽ ghi nhận lỗi đó nhưng vẫn tiếp tục xử lý các item hợp lệ còn lại trong danh sách.
Bạn có thể tùy chỉnh hành vi này sâu hơn bằng cách sử dụng cổng ra dành riêng cho lỗi (error output) để phân luồng và xử lý riêng các item thất bại.
Ứng dụng thực tế
Giả sử bạn có một workflow lặp qua 1.000 từ khóa để tìm kiếm thông tin. Nếu từ khóa thứ 50 có lỗi cú pháp, với cài đặt mặc định, 950 từ khóa còn lại sẽ không được xử lý. Khi bật “Continue On Fail”, 999 từ khóa vẫn được xử lý bình thường, chỉ item lỗi bị bỏ qua (hoặc được gửi sang một nhánh khác để xử lý riêng).
Lưu ý khi áp dụng “continue on error”
- Luôn phân tích kỹ luồng thành công và luồng thất bại để không bỏ lọt log hay các tác vụ “xử lý lại” khi cần.
- Hạn chế sử dụng với các tác vụ hệ trọng (ví dụ: chuyển tiền, xác nhận giao dịch) nếu không có điều kiện hậu kiểm nghiêm ngặt.
5. Kỹ thuật polling – theo dõi tác vụ bất đồng bộ cho kết quả chắc chắn
Trong nhiều trường hợp, bạn cần yêu cầu một dịch vụ bên ngoài thực hiện một tác vụ tốn thời gian (ví dụ: tạo ảnh AI, xử lý video). Các dịch vụ này thường hoạt động bất đồng bộ: bạn gửi yêu cầu và nhận lại một task_id ngay lập tức, nhưng kết quả thực sự chỉ có sau một khoảng thời gian. Kỹ thuật polling là giải pháp hoàn hảo cho việc này, và được mô tả như sau trong workflow:
- Node Generate Image gửi một yêu cầu
POSTđể bắt đầu tác vụ tạo ảnh và nhận về mộttask_id. - Node Wait tạm dừng workflow trong một khoảng thời gian ngắn.
- Node Get Images gửi yêu cầu
GETđến một endpoint khác, sử dụngtask_idnhận được ở bước 1 để kiểm tra trạng thái của tác vụ. - Node If kiểm tra xem trường
statustrong dữ liệu trả về đã là “completed” hay chưa. - Nếu chưa, luồng sẽ đi qua node Wait1 rồi lặp lại bước 3. Nếu đã “completed”, workflow sẽ thoát khỏi vòng lặp và tiếp tục các bước tiếp theo.
Ưu điểm của polling
- Đảm bảo workflow chỉ tiếp tục khi tác vụ nền đã thực sự hoàn thành.
- Tránh việc phải đoán thời gian chờ (wait time), vốn không hiệu quả và thiếu tin cậy.
- Giúp quản lý tốt hơn các workflow phức tạp, phụ thuộc vào nhiều hệ thống bất đồng bộ.
Một số khuyến nghị khi xây dựng polling trong n8n
- Điều chỉnh khoảng thời gian chờ giữa các lần poll cho phù hợp để tránh spam API của dịch vụ đối tác.
- Thiết kế điều kiện dừng lặp an toàn (ví dụ: giới hạn số lần lặp hoặc có một nhánh xử lý khi task bị
failed).
(Bonus) Xây dựng guardrail – hàng rào bảo vệ ngăn ngừa lỗi ngoài dự kiến
Ngay cả khi bạn đã áp dụng đầy đủ các kỹ thuật trên, các lỗi không lường trước vẫn có thể xảy ra, thường là do dữ liệu đầu vào không hợp lệ. Để giảm thiểu ảnh hưởng, bạn nên thiết kế thêm các “guardrail” – các logic kiểm tra và làm sạch dữ liệu.
Workflow ví dụ đã minh họa một guardrail đơn giản:
- Node Set khởi tạo một biến
queryvới giá trị"pineapples on pizza", bao gồm cả dấu ngoặc kép. - Node Tavily 1 sử dụng một expression
{{ $json.query.replace(/\"/g, '') }}để xóa các dấu ngoặc kép này đi trước khi gửi yêu cầu đến API.
Hành động “làm sạch” dữ liệu này chính là một guardrail. Nó ngăn ngừa các lỗi tiềm ẩn do định dạng dữ liệu đầu vào không đúng như mong đợi.
Ứng dụng guardrail hiệu quả
- Thường xuyên kiểm tra log lỗi từ error workflow. Nếu phát hiện một loại lỗi lặp đi lặp lại, hãy xây dựng một guardrail để xử lý nó.
- Sử dụng các node như Set, Code, hoặc các expression để chuẩn hóa, làm sạch, và xác thực dữ liệu trước khi đưa vào các node xử lý chính.
Tóm lại, để đảm bảo sản phẩm tự động hóa n8n vận hành ổn định trong môi trường production, việc nắm vững và triển khai hợp lý các kỹ thuật xử lý lỗi như error workflow, retry, fallback LLM, continue on error, polling và guardrail là điều kiện tiên quyết. Không workflow nào miễn nhiễm với lỗi, nhưng một hệ thống chuyên nghiệp là hệ thống mà mỗi lỗi đều được ghi nhận, kiểm soát, và giảm thiểu tối đa tác động. Đầu tư vào việc xử lý lỗi một cách khoa học ngay từ đầu sẽ giúp bạn tiết kiệm thời gian, công sức và mang lại sự tin tưởng tuyệt đối vào các giải pháp tự động hóa của mình.